
Docker est devenu un outil incontournable pour tous les développeurs ou les administrateurs d’infrastructure, mais celui-ci peut paraître complexe au premier abord. On se retrouve donc aujourd’hui pour tenter de clarifier tout ça avec ce premier article de cette série consacré à Docker où l’on va découvrir les bases.
Cette série se compose de trois articles :
- Découverte des bases de Docker ;
- Conteneuriser son application Node.js ;
- Déploiement avec Docker compose
Remontons le temps
La plupart des applications nécessitent un serveur sur lequel s’exécuter. Dans le passé, il n’existait pas de solutions permettant d’isoler efficacement les applications entre elles au sein d’un même serveur. On se retrouvait donc souvent avec une application par serveur. Serveur qui était la plupart du temps surdimensionné pour les besoins de l’application et qui représentait donc un coût important pour les entreprises. De plus il pouvait être difficile de migrer une application vers un autre serveur, car cela nécessitait d’avoir le même système d’exploitation que le serveur d’origine.
L’ère de la virtualisation
L’arrivée de la virtualisation changea la donne. Celle-ci a permis de créer et d’exécuter une ou plusieurs machines virtuelles (virtual machine ou VM) sur une même machine physique. Grossièrement, une machine virtuelle est l’équivalent d’une machine physique, mais gérer de manière logicielle à l’aide de ce que l’on appelle un hyperviseur. L’hyperviseur est une plate-forme de virtualisation qui permet à plusieurs systèmes d’exploitation de travailler sur une même machine physique en même temps.
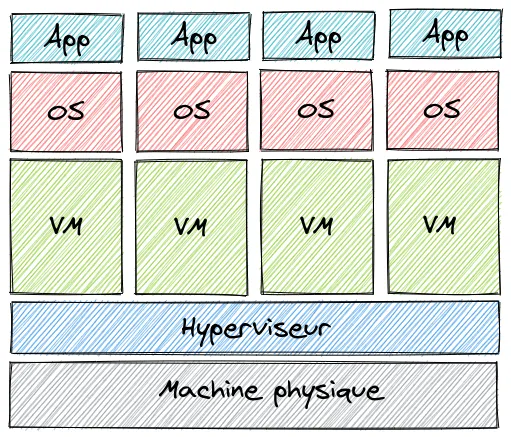
Mais la virtualisation n’est pas parfaite. Chaque machine virtuelle dispose de son propre système d’exploitation qui peut consommer beaucoup de ressources (CPU, mémoire, disques, etc.). Nous devons également gérer la maintenance de ces systèmes d’exploitation (mise à jour par exemple) et certains d’entre eux nécessitent même l’achat de licence. Au final, on se retrouve à devoir maintenir des systèmes d’exploitation alors que ce qui nous intéresse ce sont surtout les applications qui vont tourner sur ceux-ci.
La conteneurisation à la rescousse
La conteneurisation ressemble beaucoup à la virtualisation à un détail près, chaque conteneur (pour simplifier, c’est plus ou moins l’équivalent de la machine virtuelle) ne dispose pas de son propre noyau de système d’exploitation, mais va utiliser celui de la machine hôte. Cela permet donc de libérer des ressources, de réduire les opérations de maintenance liées aux systèmes d’exploitation, mais également les coûts de licences de ceux-ci. De plus, les conteneurs sont plus rapides à démarrer qu’une machine virtuelle du fait de l’absence du système d’exploitation, mais également plus facilement transportable d’une infrastructure à une autre.
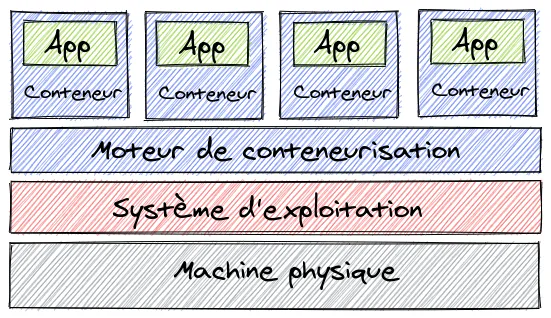
Pour faire simple, un conteneur virtualise un système d’exploitation et réutilise le noyau du système d’exploitation de la machine hôte alors qu’une machine virtuelle virtualise une machine physique à l’aide de l’hyperviseur.
Et Docker dans tout ça ?
Même si l’histoire sur l’origine de Docker est intéressante, je ne vais pas vous la raconter et plutôt me concentrer sur son fonctionnement et son utilisation (Sinon vous allez vous endormir déjà que l’article est assez long…). Si vous êtes néanmoins intéressé, je vous invite à aller lire la page Wikipédia de Docker.
Concrètement c’est quoi Docker ?
Docker est simplement un moteur de conteneurisation permettant de créer, gérer et orchestrer des conteneurs. Voyons rapidement les différents composants de Docker.
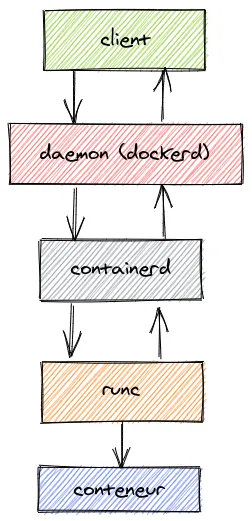
Client
Le client est une interface en ligne de commande (CLI) permettant d’interagir facilement avec le daemon Docker. Nous reviendrons sur l’utilisation du client lorsque nous verrons les différentes commandes.
daemon (dockerd)
Le daemon (dockerd) expose une API (utilisé par le client) permettant d’interagir avec les couches plus basses de Docker (containerd).
containerd
containerd est un runtime de haut niveau permettant de gérer le cycle de vie des conteneurs (démarrage, arrêt, suppression, etc.), mais également de gérer les volumes, le réseau ou encore les images (nous reviendrons sur ces termes dans la suite de l’article). Il s’agit en quelque sorte d’un superviseur de conteneurs.
runc
runc est un runtime de bas niveau permettant de démarrer les conteneurs en interagissant avec le système d’exploitation. L’Open Container Initiative (OCI), un projet de la Fondation Linux, a conçu des standards pour les conteneurs notamment pour le format des images et l’exécution des conteneurs (runtime). runc est donc une l’implémentation de ce dernier.
Il existe de nombreux autres runtimes sur le marché, le monde de la conteneurisation est un joyeux bordel et il est souvent difficile de s’y retrouver. Si vous voulez en savoir plus sur les runtimes je vous conseille cet article de la grotte du barbu ou encore cette vidéo de xavki.
Installation de Docker
Avant de continuer, nous allons installer Docker. Il existe une version pour Linux, Windows et Mac.
Linux
On va s’intéresser ici à la procédure d’installation sur Ubuntu, si vous utilisez une autre distribution, je vous invite à aller lire la documentation officielle.
On commence par mettre à jour la liste des paquets existants :
sudo apt-get updateOn installe toutes les dépendances requises pour l’installation :
sudo apt-get install \ apt-transport-https \ ca-certificates \ curl \ gnupg \ lsb-releasePuis on ajoute la clé GPG du dépôt de Docker :
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpgOn indique ensuite que l’on souhaite utiliser la version stable du dépôt de Docker :
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/nullOn met à jour une nouvelle fois la liste des paquets existants :
sudo apt-get updatePour finir, nous pouvons installer Docker :
sudo apt-get install docker-ce docker-ce-cli containerd.ioVérifions maintenant que tout fonctionne :
sudo docker -vDocker version 20.10.6, build 370c289Si vous voulez exécuter les commandes Docker sans être root, il suffit de créer un groupe docker:
sudo groupadd dockerEt d’ajouter votre nom d’utilisateur à ce groupe :
sudo usermod -aG docker $USERWindows
Concernant l’installation sous Windows, celle-ci est très simple. Il suffit de télécharger Docker Desktop que vous trouverez sur le site officiel et d’installer celui-ci en suivant les instructions.
Mac
L’installation sur Mac est similaire à celle de Windows. Il suffit de télécharger Docker Desktop et de suivre les instructions. Rendez-vous sur le site officiel pour le télécharger.
Play with Docker
Si vous souhaitez tester Docker sans l’installer, vous pouvez utiliser le site “Play with Docker”. Il vous faudra juste créer un compte sur le site de Docker, et une fois connecté vous aurez accès à une sandbox d’une durée de 4 heures.
Passons aux choses sérieuses
J’ai parlé tout à l’heure d’images, de conteneurs, de volumes ou encore de réseaux, tout ce petit monde forme ce que l’on appelle les objets Docker. Il est temps de s’intéresser à chacun d’eux et de passer à la pratique.
Les images
Une image contient tout ce qui est nécessaire au fonctionnement d’une application c’est-à-dire le code de celle-ci, les dépendances, la configuration, les variables d’environnement, etc. Si vous êtes familiers avec l’utilisation des machines virtuelles, c’est plus au moins l’équivalent des templates. C’est à partir de ces images que nous pouvons créer les conteneurs, si l’on veut faire un parallèle avec la programmation, on peut considérer qu’une image est une classe et un conteneur une instance de celle-ci.
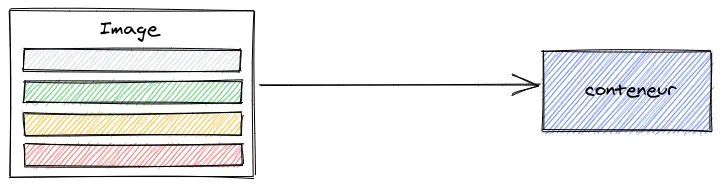
Je vous rappelle que la conteneurisation permet de virtualiser un système d’exploitation et réutilise le noyau du système d’exploitation de la machine hôte, contrairement aux machines virtuelles qui elles virtualisent une machine physique. De ce fait les images sont généralement très petites puisque celles-ci embarquent uniquement le strict minimum pour faire tourner les applications.
Récupérer des images
Lorsque l’on installe Docker, aucune image n’est présente. Nous pouvons le vérifier avec la commande suivante permettant de lister les images :
docker image lsOn remarque qu’il n’y a aucune image de présente :
REPOSITORY TAG IMAGE ID CREATED SIZEPour récupérer une image (ou parle de pulling), il suffit d’utiliser la commande suivante :
docker image pull repository:tagPar exemple, si l’on souhaite récupérer l’image de la dernière version de Node.js, il suffit d’utiliser la commande suivante :
docker image pull node:latestComme vous pouvez le voir, plusieurs éléments ont été téléchargés (on reviendra dessus un peu plus tard) :
latest: Pulling from library/noded960726af2be: Pull completee8d62473a22d: Pull complete8962bc0fad55: Pull complete65d943ee54c1: Pull complete532f6f723709: Pull completef8463f32765b: Pull complete39c1cd906e85: Pull complete9b89015c57b4: Pull complete6a93d724110f: Pull completeDigest: sha256:ddc2ebfc3759299afb2085bba7648416e016b326389323a257c4f8d1da097c9cStatus: Downloaded newer image for node:latestdocker.io/library/node:latestVérifions maintenant que l’image est bien présente sur notre machine :
docker image lsREPOSITORY TAG IMAGE ID CREATED SIZEnode latest 7493e35c7ffa 13 days ago 908MBC’est bon ! On a une image Docker de Node.js sur notre machine. Maintenant vous vous demandez sûrement où a-t-on récupéré cette image ?
Les images sont centralisées dans ce qu’on appelle des image registries qui sont en quelque sorte des dépôts permettant de partager et de stocker les images Docker à l’instar de npm ou packagist qui eux permettent de stocker et de partager respectivement des librairies JavaScript et PHP.
Le registry par défaut est le Docker Hub, mais il en existe bien entendu d’autres. On peut d’ailleurs voir les registries utilisés par Docker avec la commande suivante :
docker infoOn a tout un tas d’informations, mais celle qui nous intéresse est Registry :
Server:... Registry: https://index.docker.io/v1/...Un registry peut contenir plusieurs repositories qui peuvent contenir plusieurs versions d’images… Ok vous avez du mal à suivre ? Je vais vous faire un schéma ça sera beaucoup plus simple :
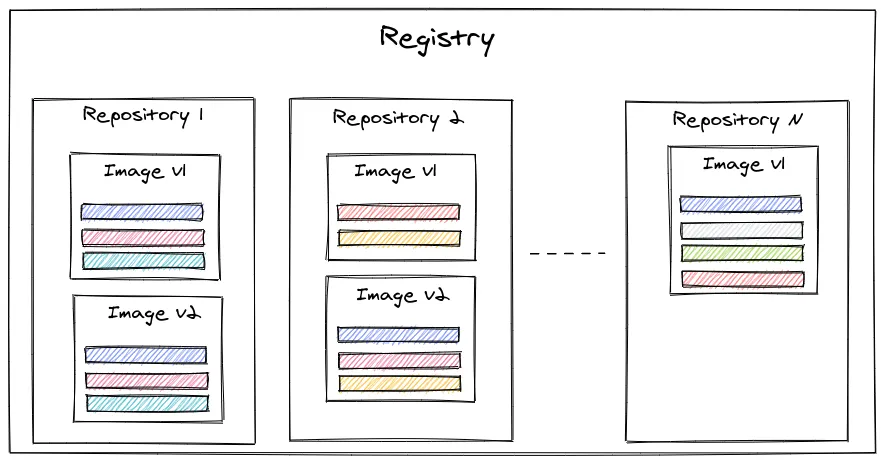
Si l’on reprend l’image de Node.js, celle-ci se trouve sur le registry https://index.docker.io/v1/ (le Docker Hub), le repository c’est simplement le nom de l’image ici node, la version latest est quant à elle, un tag correspondant à la dernière version de l’image de Node.js (la version 16 au moment de l’écriture de cet article).
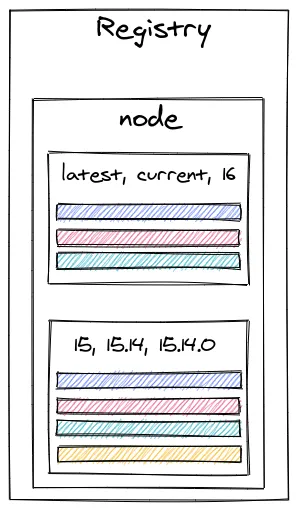
Comme on peut le voir pour une même image, il peut y avoir plusieurs tags. Si par exemple nous récupérons l’image de Node.js ayant le tag _16_ :
docker image pull node:16Et qu’on liste les images :
docker image lsREPOSITORY TAG IMAGE ID CREATED SIZEnode 16 7493e35c7ffa 13 days ago 908MBnode latest 7493e35c7ffa 13 days ago 908MBOn pourrait penser que l’on a deux images différentes, mais si l’on regarde de plus près on se rend compte que les ids des images sont les mêmes, preuve qu’il s’agit bien de la même image.
Une image est découpée en plusieurs couches
Avant de voir les principales commandes concernant les images, il faut que je vous parle d’un concept très important les concernant, il s’agit des couches (layer). Rappelez-vous lorsque l’on a récupéré l’image de Node.js, plusieurs éléments ont été téléchargés :
latest: Pulling from library/noded960726af2be: Pull completee8d62473a22d: Pull complete8962bc0fad55: Pull complete65d943ee54c1: Pull complete532f6f723709: Pull completef8463f32765b: Pull complete39c1cd906e85: Pull complete9b89015c57b4: Pull complete6a93d724110f: Pull completeDigest: sha256:ddc2ebfc3759299afb2085bba7648416e016b326389323a257c4f8d1da097c9cStatus: Downloaded newer image for node:latestdocker.io/library/node:latestChaque élément est en fait ce que l’on appelle une couche (ou layer), chaque couche est en lecture seule et l’ensemble de celles-ci forme une image.
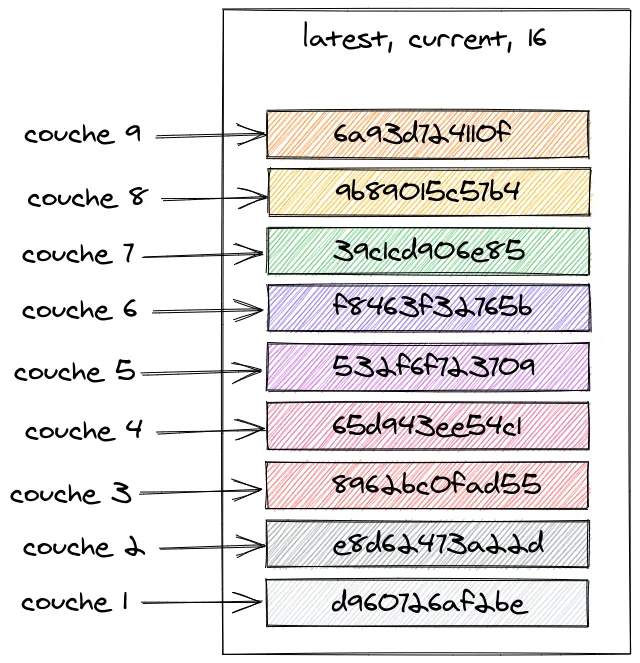
Pour faire simple, chaque couche correspond à une étape de création de l’image et contient un ensemble de fichiers créés lors de cette étape.
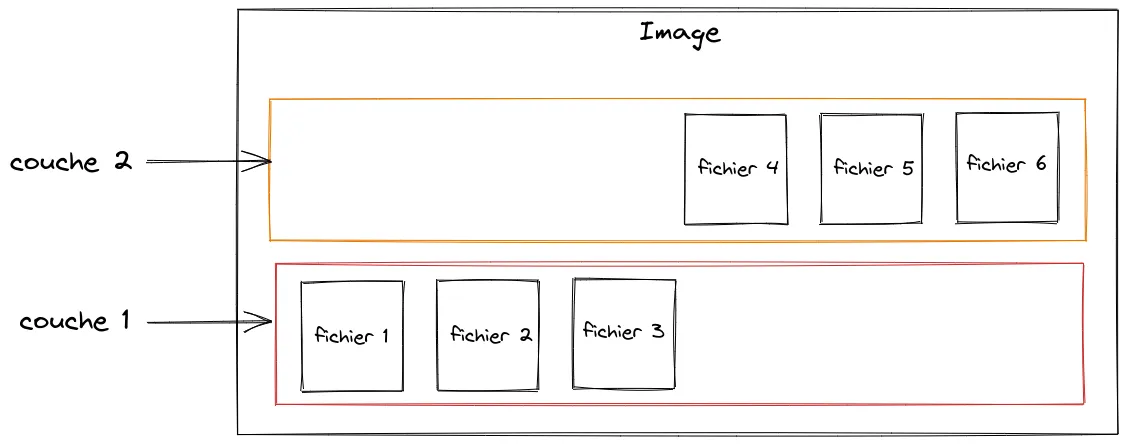
Docker utilise un système de fichier permettant de fusionner ces différentes couches et de présenter une vue unifiée, c’est ce qu’on appelle un “Union File System”.
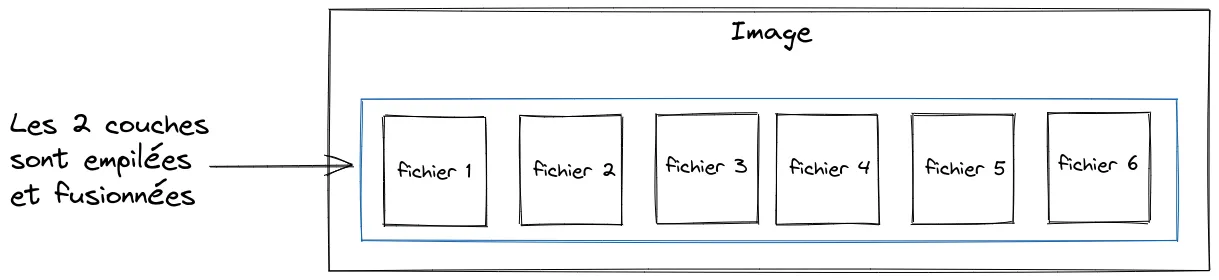
Sachez également que les couches peuvent être partagées entre plusieurs images, mais on en reparlera dans le prochain article, où nous nous intéresserons à la création d’images.
Les principales commandes
Documentation officielle : https://docs.docker.com/engine/reference/commandline/image
Voyons maintenant les principales commandes concernant les images.
Récupérer une image
Documentation officielle : https://docs.docker.com/engine/reference/commandline/image_pull
Pour rappel, pour récupérer (pull) une image il suffit d’utiliser la commande suivante :
docker image pull [OPTIONS] NAME[:TAG|@DIGEST]Si l’on souhaite par exemple télécharger la version 16 de Node.js utilisant Alpine, qui est une distribution Linux ultra légère, il suffit d’utiliser la commande suivante :
docker image pull node:16-alpine3.11Il est également possible de ne pas préciser de tag :
docker image pull nodeCe qui a pour effet de récupérer l’image ayant comme tag latest, si celui-ci existe.
Je vous déconseille d’utiliser le tag latest qui ne garantit pas qu’il s’agisse de la dernière version ! Préférez un tag avec un numéro de version.
Vous pouvez également télécharger toutes les images d’un repository avec l’option -a ou --all-tags, mais pour des raisons évidentes, éviter de le faire !
Lister les images
Documentation officielle : https://docs.docker.com/engine/reference/commandline/image_ls
On a également vu la commande permettant de lister les images :
docker image ls [OPTIONS] [REPOSITORY[:TAG]]Quelques options utiles :
- Lister toutes les images:
--all,-a - Appliquer un filtre :
--filter. Par exemple afficher les images sans tags :docker image ls --filter dangling=true
Supprimer les images
Documentation officielle : https://docs.docker.com/engine/reference/commandline/image_rm
docker image rm [OPTIONS] IMAGE [IMAGE...]Supprimer les images non taguées
Documentation officielle : https://docs.docker.com/engine/reference/commandline/image_prune
docker image pruneIl est possible de supprimer les images non taguées et inutilisées par des conteneurs via l’option -a (ou -all).
Rechercher une image
Documentation officielle : https://docs.docker.com/engine/reference/commandline/search/
Il est également possible de rechercher une image via la commande suivante :
docker search TERMPar exemple si on cherche l’image de Redis :
docker search redisOn obtient le résultat suivant :
NAME DESCRIPTION STARS OFFICIAL AUTOMATEDredis Redis is an open source key-value store that… 9518 [OK]bitnami/redis Bitnami Redis Docker Image 183 [OK]sameersbn/redis 83 [OK]grokzen/redis-cluster Redis cluster 3.0, 3.2, 4.0, 5.0, 6.0, 6.2 78rediscommander/redis-commander Alpine image for redis-commander - Redis man… 59 [OK]redislabs/redisearch Redis With the RedisSearch module pre-loaded… 34redislabs/redisinsight RedisInsight - The GUI for Redis 30redislabs/redis Clustered in-memory database engine compatib… 30oliver006/redis_exporter Prometheus Exporter for Redis Metrics. Supp… 25arm32v7/redis Redis is an open source key-value store that… 23redislabs/rejson RedisJSON - Enhanced JSON data type processi… 23bitnami/redis-sentinel Bitnami Docker Image for Redis Sentinel 22 [OK]redislabs/redisgraph A graph database module for Redis 15 [OK]redislabs/redismod An automated build of redismod - latest Redi… 13 [OK]arm64v8/redis Redis is an open source key-value store that… 12webhippie/redis Docker images for Redis 11 [OK]s7anley/redis-sentinel-docker Redis Sentinel 10 [OK]insready/redis-stat Docker image for the real-time Redis monitor… 10 [OK]goodsmileduck/redis-cli redis-cli on alpine 9 [OK]circleci/redis CircleCI images for Redis 7 [OK]centos/redis-32-centos7 Redis in-memory data structure store, used a… 5clearlinux/redis Redis key-value data structure server with t… 3tiredofit/redis Redis Server w/ Zabbix monitoring and S6 Ove… 1 [OK]wodby/redis Redis container image with orchestration 1 [OK]xetamus/redis-resource forked redis-resource 0 [OK]Personnellement j’utilise que très rarement cette commande, je vais plutôt rechercher directement sur le Docker Hub.
Les conteneurs
Un conteneur est simplement un environnement d’exécution de processus isolé du reste du système, il n’est donc pas possible pour un conteneur d’accéder aux ressources d’un autre conteneur ou de la machine hôte, tout du moins si on ne l’a pas explicitement autorisé.
Démarrer un conteneur
J’ai fait précédemment le parallèle avec la programmation en disant qu’une image était une classe et un conteneur l’instance de cette classe. Créons donc un conteneur à partir d’une image. Nous allons commencer par le traditionnel hello world, et utiliser la commande docker run, qui comme son nom l’indique, permet d’exécuter un nouveau conteneur :
docker run hello-worldVous devriez avoir le résultat suivant :
Unable to find image 'hello-world:latest' locallylatest: Pulling from library/hello-worldb8dfde127a29: Pull completeDigest: sha256:5122f6204b6a3596e048758cabba3c46b1c937a46b5be6225b835d091b90e46cStatus: Downloaded newer image for hello-world:latest
Hello from Docker!This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps: 1. The Docker client contacted the Docker daemon. 2. The Docker daemon pulled the "hello-world" image from the Docker Hub. (amd64) 3. The Docker daemon created a new container from that image which runs the executable that produces the output you are currently reading. 4. The Docker daemon streamed that output to the Docker client, which sent it to your terminal.
To try something more ambitious, you can run an Ubuntu container with: $ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID: https://hub.docker.com/
For more examples and ideas, visit: https://docs.docker.com/get-started/Comme le message l’indique, voici ce qu’il s’est passé :
- Le client Docker a envoyé l’instruction de démarrer un nouveau conteneur de l’image
hello-worldau daemon ; - Le daemon Docker à récupérer l’image
hello-worlddepuis le Docker Hub (si celle-ci n’était pas déjà présente en local) ; - Le daemon a créé un nouveau conteneur (à l’aide de
containerdetrunc) depuis l’imagehello-worldet exécute le programme contenu dans celle-ci ; - Le daemon a ensuite transféré la sortie du conteneur vers le client Docker pour ensuite l’afficher sur le terminal.
Oui c’est tout ce n’est pas très compliqué ! Bon, comme le dit le message faisons quelque chose de plus ambitieux et démarrons un conteneur d’Ubuntu :
docker run -it ubuntu bashOn utilise les options -it, permettant d’activer le mode interactif (l’option i) en attachant le flux entrant (STDIN) du conteneur à la machine hôte pour pouvoir interagir avec celui-ci et de connecter un terminal (l’option t) au conteneur. On indique également le nom de l’image ici ubuntu suivi du programme à exécuter ici bash. On obtient la sortie suivante :
Unable to find image 'ubuntu:latest' locallylatest: Pulling from library/ubuntu345e3491a907: Pull complete57671312ef6f: Pull complete5e9250ddb7d0: Pull completeDigest: sha256:adf73ca014822ad8237623d388cedf4d5346aa72c270c5acc01431cc93e18e2dStatus: Downloaded newer image for ubuntu:latestroot@d947d5b99b48:/#On remarque que nous avons le prompt (root@d947d5b99b48:/#) qui indique que nous sommes actuellement “connecté” au conteneur. Testons une commande, ls -al par exemple :
root@d947d5b99b48:/# ls -altotal 56drwxr-xr-x 1 root root 4096 Jun 3 09:36 .drwxr-xr-x 1 root root 4096 Jun 3 09:36 ..-rwxr-xr-x 1 root root 0 Jun 3 09:36 .dockerenvlrwxrwxrwx 1 root root 7 Apr 16 05:11 bin -> usr/bindrwxr-xr-x 2 root root 4096 Apr 15 2020 bootdrwxr-xr-x 5 root root 360 Jun 3 09:36 devdrwxr-xr-x 1 root root 4096 Jun 3 09:36 etcdrwxr-xr-x 2 root root 4096 Apr 15 2020 homelrwxrwxrwx 1 root root 7 Apr 16 05:11 lib -> usr/liblrwxrwxrwx 1 root root 9 Apr 16 05:11 lib32 -> usr/lib32lrwxrwxrwx 1 root root 9 Apr 16 05:11 lib64 -> usr/lib64lrwxrwxrwx 1 root root 10 Apr 16 05:11 libx32 -> usr/libx32drwxr-xr-x 2 root root 4096 Apr 16 05:11 mediadrwxr-xr-x 2 root root 4096 Apr 16 05:11 mntdrwxr-xr-x 2 root root 4096 Apr 16 05:11 optdr-xr-xr-x 428 root root 0 Jun 3 09:36 procdrwx------ 2 root root 4096 Apr 16 05:32 rootdrwxr-xr-x 1 root root 4096 Apr 23 22:21 runlrwxrwxrwx 1 root root 8 Apr 16 05:11 sbin -> usr/sbindrwxr-xr-x 2 root root 4096 Apr 16 05:11 srvdr-xr-xr-x 13 root root 0 Jun 3 09:36 sysdrwxrwxrwt 2 root root 4096 Apr 16 05:33 tmpdrwxr-xr-x 1 root root 4096 Apr 16 05:11 usrdrwxr-xr-x 1 root root 4096 Apr 16 05:32 varNous avons donc un conteneur Ubuntu qui est totalement isolé du reste ! Continuons et lançons la commande suivante :
root@d947d5b99b48:/# ps -lF S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD4 S 0 1 0 0 80 0 - 1029 do_wai pts/0 00:00:00 bash0 R 0 12 1 0 80 0 - 1456 - pts/0 00:00:00 psOn remarque que l’on a un seul programme en cours d’exécution (si l’on ignore la commande ps) qui est bash, celui que l’on a indiqué lors du démarrage du conteneur. Son PID est donc 1 ce qui indique qu’il s’agit du processus principal (aussi appelé init), lorsque celui-ci se termine, le conteneur s’arrête.
Sortons donc du conteneur via la commande exit :
root@d947d5b99b48:/# exitOn se retrouve donc à nouveau sur la machine hôte. Vérifions maintenant que le conteneur est bien arrêté :
docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMESC’est bien le cas !
Faisons un autre test, mais cette fois-ci avec Apache. Lançons la commande suivante :
docker run -dit --name test-apache2 -p 8080:80 httpdOn a avons plusieurs nouvelles options :
-d(ou--detach) : Permets de démarrer le conteneur en arrière-plan ;--name: Permets de donner un nom au conteneur (par défaut Docker génère un nom aléatoire);-p(ou--publish) : Permets de transférer le trafic du port 8080 de la machine hôte vers le port 80 du conteneur (-p port_hote:port_conteneur).
On obtient l’affiche suivant :
41731272069ec4830b82a40af23b02f0aaca1e916a37561d3d5d1f0451084eeeQui est simplement l’identifiant du conteneur.
Rendez-vous à l’adresse suivante http://localhost:8080/ et vous devriez avoir la page suivante qui s’ouvre :
Se “connecter” à conteneur en cours d’exécution
Notre conteneur Apache est exécuté en arrière-plan (via l’option -d), mais il est possible de se “connecter” à celui-ci via la commande suivante :
docker exec -ti test-apache2 bashCette commande permet d’exécuter une commande (ou un programme) au sein d’un conteneur. Dans notre cas, nous souhaitons exécuter le programme bash, d’activer le mode interactif (l’option -i) et de connecter un terminal (l’option -t).
Une fois à l’intérieur du conteneur, ajoutons une page HTML :
root@41731272069e:/usr/local/apache2# echo "<html><body><h1>Docker c'est cool</h1></body></html>" > /usr/local/apache2/htdocs/docker.htmlVérifions ensuite que tout fonctionne http://localhost:8080/docker.html :
Le cycle de vie d’un conteneur
Il est possible de stopper, mettre en pause ou même supprimer un conteneur. Par exemple, pour stopper notre conteneur Apache, il suffit d’utiliser la commande suivante :
docker container stop test-apache2Si nous vérifions les conteneurs en cours d’exécution via la commande docker container ls (vous pouvez également utiliser docker ps) :
docker container lsCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMESNous remarquons qu’il n’y a aucun conteneur en cours d’exécution. Pour voir l’ensemble des conteneurs présent, même ceux stoppés, il suffit d’ajouter l’option -a (ou --all) :
docker container ls -aCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES41731272069e httpd "httpd-foreground" 2 hours ago Exited (0) 1 minutes ago test-apache2On remarque que le statut de notre conteneur est Exited, le conteneur est donc bien stoppé.
Il est également possible de supprimer un conteneur via la commande docker container rm :
docker container rm test-apache2Vérifions maintenant que le conteneur est bien supprimé :
docker container ls -aCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMESC’est bien le cas ! Petite information, le conteneur doit d’abord être stoppé pour pouvoir le supprimer, dans le cas contraire vous aurez le message suivant :
Error response from daemon: You cannot remove a running container 342a19582b133c321880ceb6484e59a18a22303c07555383419a624219e2b3a6. Stop the container before attempting removal or force removeVous pouvez néanmoins forcer la suppression via la commande -f :
docker container rm -f test-apache2Mais je vous le déconseille, car le conteneur ne pourra pas se terminer proprement puisque l’option -f envoi le signal SIGKILL au processus principal du conteneur (celui avec le PID 1) qui ne laisse donc aucun délai à celui-ci pour se terminer proprement contrairement à la commande docker container stop qui, elle, envoie le signal SIGTERM et laisse 10 secondes au conteneur de se terminer, et envoie le signal SIGKILL si le conteneur ne s’est pas terminé avant.
Il est également possible de mettre en pause un conteneur via la commande docker container pause :
docker container pause test-apache2Et de le sortir de cet état de pause via la commande docker container unpause :
docker container unpause test-apache2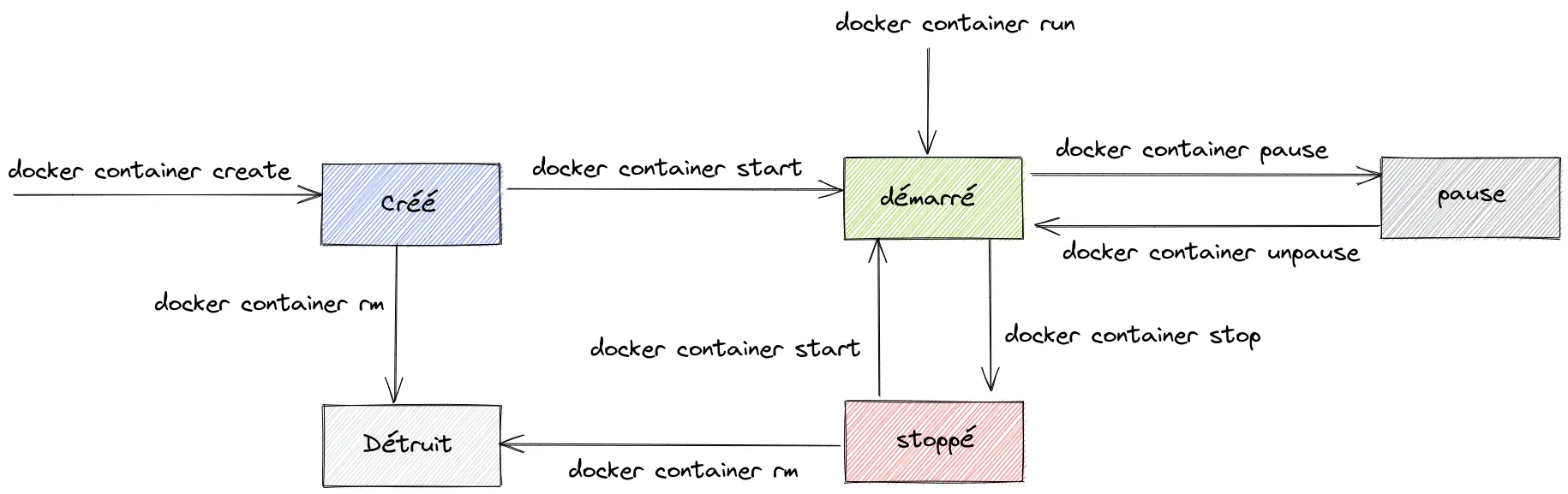
Les politiques de redémarrage
Il est possible de spécifier à la commande docker container run, via l’option --restart, une politique de redémarrage du conteneur. Il en existe quatre :
no: Ne redémarre pas le container automatiquement. Il s’agit de l’option par défaut ;always: Redémarre le container quand il est stoppé. Si le conteneur est arrêté manuellement (via la commandedocker container stop), le container redémarrera si le daemon redémarre ;unless-stopped: Idem quealways, mais le container ne redémarrera pas si le daemon redémarre ;on-failure: Redémarre lorsque le container s’est arrêté suite à une erreur (le conteneur s’est terminé avec un code de retour différent de 0).
Reprenons notre exemple précédent avec Ubuntu et rajoutons la politique de redémarrage always :
docker run -it --restart always ubuntu bashOn a vu tout à l’heure que le processus bash avait le PID 1, lorsque nous utilisons la commande exit, nous quittons donc ce processus. Comme il s’agit du processus principal, le conteneur s’arrête également. Mais avec la politique de redémarrage always le conteneur s’arrête bien, mais redémarre.
On peut s’en assurer avec la commande docker container ls :
docker container lsCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES8af5aa95ca53 ubuntu "bash" 2 minutes ago Up 2 seconds happy_goodallLe conteneur est en cours d’exécution depuis 2 secondes, donc celui-ci a bien redemarré.
Voyons maintenant la différence entre always et unless-stopped. Créons un premier conteneur avec la politique always :
docker run -d --restart always --name always-container redisEt un autre avec la politique unless-stopped :
docker run -d --restart unless-stopped --name unless-stopped-container redisOn vérifie que nos deux conteneurs sont en cours d’exécution :
docker container lsCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES43e7096da0d2 redis "docker-entrypoint.s…" 3 seconds ago Up 3 seconds 6379/tcp unless-stopped-container7a3b9d725754 redis "docker-entrypoint.s…" 10 seconds ago Up 10 seconds 6379/tcp always-containerPuis on les arrête :
docker container stop always-container unless-stopped-containerVérifions :
docker container lsCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMESRedémarrons le daemon Docker :
sudo service docker restartUne fois le daemon Docker redémarré, vérifions nos deux conteneurs :
docker container ls -aCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES43e7096da0d2 redis "docker-entrypoint.s…" 4 minutes ago Exited (0) 2 minutes ago unless-stopped-container7a3b9d725754 redis "docker-entrypoint.s…" 5 minutes ago Up About a minute 6379/tcp always-containerOn remarque que le conteneur always-container a bien redémarré contrairement au conteneur unless-stopped-container.
Les principales commandes
Documentation officielle : https://docs.docker.com/engine/reference/commandline/container
Voyons maintenant les principales commandes concernant les conteneurs.
Démarrer un conteneur
Documentation officielle : https://docs.docker.com/engine/reference/commandline/container_run/
docker container run [OPTIONS] IMAGE [COMMAND] [ARG...]Quelques options utiles :
- Binder les ports :
--publish , -p port_hote:port_conteneur - Mode interactive :
--interactive , -i - Ouvrir un terminal :
--tty , -t - Supprimer après arrêt :
--rm - Associer un nom :
--name - Démarrer en arrière-plan :
--detach , -d - Passer des variables d’environnement :
--env,-e
Arrêter un conteneur
Documentation officielle : https://docs.docker.com/engine/reference/commandline/container_stop
docker container stop [OPTIONS] CONTAINER [CONTAINER...]Cette commande envoie le signal SIGTERM au processus principal (PID 1) et attend 10 secondes. Si le processus ne s’est pas terminé, elle envoie le signal SIGKILL.
Il est tout de fois possible de modifier ce délai de 10 secondes via l’option -t (ou --time) en spécifiant le nombre de secondes avant d’envoyer le signal SIGKILL :
docker container stop -t 30 mon_conteneurVous pouvez soit spécifier le nom du conteneur soit son identifiant.
Supprimer les conteneurs
Documentation officielle : https://docs.docker.com/engine/reference/commandline/container_rm/
docker container rm [OPTIONS] CONTAINER [CONTAINER...]Les conteneurs doivent être arrêtés pour pouvoir être supprimés, dans le cas contraire il faudra utiliser l’option -f (ou --force) pour forcer l’arrêt, mais cela a pour conséquence d’envoyer le signal SIGKILL sans laisser le temps aux conteneurs de se terminer proprement.
Supprimer tous les conteneurs à l’arrêt
Documentation officielle : https://docs.docker.com/engine/reference/commandline/container_prune
docker container pruneExécuter une commande dans un conteneur
Documentation officielle : https://docs.docker.com/engine/reference/commandline/container_exec
docker container exec [OPTIONS] CONTAINER COMMAND [ARG...]Quelques options utiles :
- Mode interactive :
--interactive , -i - Ouvrir un terminal :
--tty , -t
Lister les conteneurs
Documentation officielle : https://docs.docker.com/engine/reference/commandline/container_ls
docker container ls [OPTIONS]Si vous souhaitez afficher tous les conteneurs (même ceux à l’arrêt) il suffit d’ajouter l’option -a (ou --all).
La persistance des données
On a vu que les images comprenaient plusieurs couches (layers) en lecture seule, par contre ce que je ne vous ai pas dit c’est que lors de la création d’un conteneur, une couche en lecture/écriture est ajoutée.
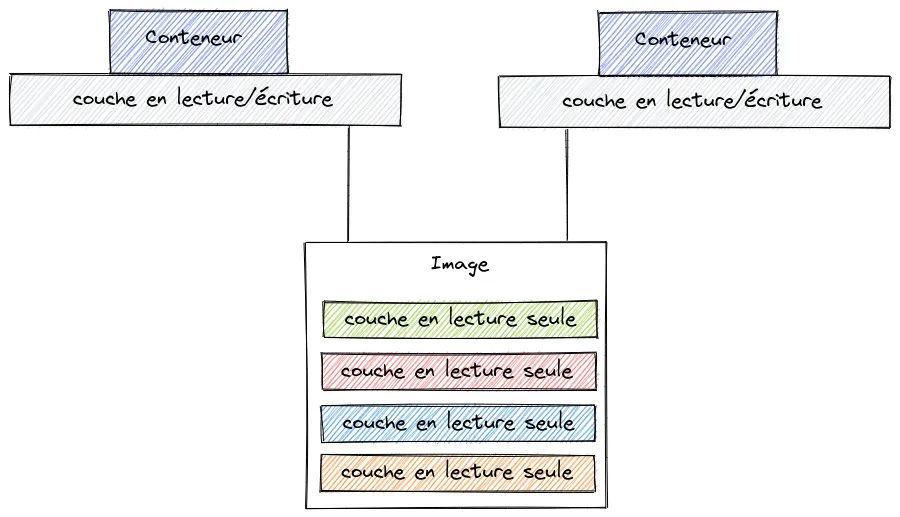
Malheureusement cette couche est éphémère, lorsque l’on supprime un conteneur cette couche est également supprimée, cela signifie que toutes les modifications seront perdues. Voyons deux solutions que Docker nous offre pour répondre à cette problématique à savoir :
- Les montages liés (bind mount) ;
- Les volumes nommés.
Les montages liés (bind mount)
La première solution est très simple, il s’agit de lier un répertoire de la machine hôte à un répertoire du conteneur. Pour cela il suffit d’utiliser l’option -v de la commande docker container run et de spécifier le répertoire de la machine hôte ainsi que celui du conteneur.
Reprenons l’exemple de notre conteneur Apache :
docker run -dit --name test-apache2 -p 8080:80 -v /home/arkerone/docker/apache-test:/usr/local/apache2/htdocs httpdIci nous avons lié le répertoire /home/arkerone/docker/apache-test de la machine hôte au répertoire /usr/local/apache2/htdocs du conteneur.
Il est également possible d’utiliser l’option --mount comme ceci :
docker run -dit --name test-apache2 -p 8080:80 --mount type=bind,src=/home/arkerone/docker/apache-test,dst=/usr/local/apache2/htdocs httpdCelle-ci est un peu plus verbeuse, nous définissons le type de montage (ici bind) à l’aide de la clé type ainsi que le répertoire de la machine hôte à l’aide de la clé src et le répertoire du conteneur à l’aide de la clé dst.
Créons un fichier index.html dans le répertoire /home/arkerone/docker/apache-test de la machine hôte et ajoutons ce code :
<!doctype html><html lang="en"><head> <meta charset="utf-8"> <title>Code Heroes - Docker</title></head><body> <h1> Hello de la machine hôte </h1></body></html>Rendons-nous maintenant à l’adresse http://localhost:8080 :

Ça fonctionne bien, mais, il y a tout de même un problème avec cette solution. Les montages liés sont dépendants de la structure du système de fichiers de la machine hôte, vous devez donc faire attention à ne pas modifier cette structure par erreur. De plus cela peut poser des problèmes de sécurité puisque vous autorisez un conteneur, censé être isolé de la machine hôte, à pouvoir modifier la structure du système de fichiers.
Les volumes nommés
La solution au problème précédent est d’utiliser des volumes nommés. Les volumes nommés sont contrairement aux montages liés, totalement gérés par Docker et sont, par conséquent, indépendants de la structure du système de fichier de la machine hôte. Pour créer un volume nommé, nous devons utiliser la commande suivante :
docker volume create [NAME]Créons donc un volume test-apache2-vol :
docker volume create test-apache2-volVérifions que celui-ci est bien créé à l’aide de la commande docker volume ls :
docker volume lsDRIVER VOLUME NAMElocal test-apache2-volReprenons notre précédent exemple et créons un conteneur utilisant ce volume :
docker run -dit --name test-apache2-1 -p 8080:80 -v test-apache2-vol:/usr/local/apache2/htdocs httpdOn utilise, tout comme les montages liés, l’option -v, mais cette fois-ci en spécifiant le nom du volume plutôt qu’un répertoire de la machine hôte. À noter que si le volume n’existe pas, Docker se charge de la créer.
Il est également possible d’utiliser l’option --mount comme ceci, mais attention cette fois-ci le volume doit d’abord avoir été créé :
docker run -dit --name test-apache2-1 -p 8080:80 --mount type=volume,src=test-apache2-vol,dst=/usr/local/apache2/htdocs httpdContrairement aux montages liés, il n’est pas possible de modifier les fichiers depuis la machine hôte (Je vous mens un peu puisque c’est possible, mais ce n’est pas du tout recommandé).
Allons donc modifier la page d’accueil d’Apache directement depuis le conteneur. Pour cela connectons-nous au conteneur :
docker exec -ti test-apache2-1 bashPuis modifions la page d’accueil :
root@f30aa82275e4:/usr/local/apache2# echo "<html><body><h1>Hello du volume Docker</h1></body></html>" > /usr/local/apache2/htdocs/index.htmlVérifions ensuite depuis la machine hôte http://localhost:8080 :

Créons un second conteneur utilisant le même volume :
docker run -dit --name test-apache2-2 -p 8081:80 --mount type=volume,src=test-apache2-vol,dst=/usr/local/apache2/htdocs httpdPuis rendons-nous à l’adresse suivante depuis la machine hôte http://localhost:8081. Nous avons bien la même page web qui s’ouvre, puisque celle-ci est stockée dans le volume test-apache2-vol qui est partagé entre les deux conteneurs. Lorsque vous supprimez vos conteneurs, les données elles ne le sont pas tant que vous ne supprimez pas le volume.
Docker utilise des drivers pour gérer les différents types de volumes, par défaut il utilise le driver local qui stocke les données sur le disque de la machine hôte (var/lib/docker/volumes/ sur Linux), mais il est possible d’utiliser d’autres types de drivers permettant par exemple de stocker les données directement sur le cloud.
Montage lié ou volume nommé ?
Vous vous demandez sûrement quand utiliser un montage lié et quand utiliser un volume nommé. Comme nous l’avons vu les montages liés permettent comme leurs noms l’indiquent de lié un répertoire de la machine hôte à un répertoire du conteneur. Personnellement j’utilise les montages liés uniquement en développement. Par exemple, comme nous l’avons vu il est très simple de monter un répertoire pouvant contenir du HTML ou du PHP dans un conteneur Apache et ainsi tester son code facilement. Dans tous les autres cas, les volumes nommés sont à privilégier et c’est d’ailleurs ce que recommande la documentation officielle de Docker.
Les principales commandes
Documentation officielle : https://docs.docker.com/engine/reference/commandline/volume
Voyons maintenant les principales commandes concernant les volumes.
Créer un volume
Documentation officielle : https://docs.docker.com/engine/reference/commandline/volume_create
docker volume create [OPTIONS] [VOLUME]Lister les volumes
Documentation officielle : https://docs.docker.com/engine/reference/commandline/volume_ls
docker volume ls [OPTIONS]Supprimer un volume
Documentation officielle : https://docs.docker.com/engine/reference/commandline/volume_rm
docker volume rm [OPTIONS] VOLUME [VOLUME...]Supprimer les volumes inutilisés
Documentation officielle : https://docs.docker.com/engine/reference/commandline/volume_prune
docker volume prune [OPTIONS]Les réseaux
Petit message aux développeurs avant de continuer, je sais que beaucoup d’entre vous n’y comprennent rien aux réseaux ou du moins déteste ça, c’est pourquoi je vais tenter d’être le plus simple possible, je vais donc volontairement ignorer certains détails techniques pour ne pas vous perdre. Bref, commençons !
Les conteneurs ont souvent besoin de communiquer entre eux, par exemple une application avec une base de données comme nous le verrons dans un prochain article, ou avec le monde extérieur, c’est pourquoi une couche réseau est nécessaire.
Docker permet la création de plusieurs types de réseaux à l’aide de drivers :
bridge: Il s’agit du type de driver par défaut. Celui-ci permet aux conteneurs connectés dans le même réseau de communiquer entre eux, mais ne sont pas accessibles de l’extérieur à moins de mapper les ports comme nous l’avons vu précédemment. Par défaut Docker créer un réseau bridge nommébridge, et tous les conteneurs créés sont automatiquement connectés à celui-ci, à moins de spécifier un autre réseau ;host: Ce type de driver permet de supprimer l’isolation réseau entre les conteneurs et la machine hôte. Ceux-ci seront donc accessibles depuis l’extérieur, puisqu’ils auront l’IP de la machine hôte (ils utilisent directement l’interface réseau de la machine hôte) ;overlay: Ce type de driver permet de créer un réseau distribué entre plusieurs machines exécutant le moteur Docker ;macvlan: Ce type de driver permet d’assigner à un conteneur une adresse MAC faisant apparaître celui-ci comme un périphérique physique sur le réseau ;none: Ce type de driver permet simplement de désactiver toute couche réseau d’un conteneur.
Docker permet également d’installer d’autres drivers réseau.
Mise en pratique
Pour cet article nous allons uniquement nous intéresser au premier type de réseaux à savoir le réseau bridge. Commençons par créer un nouveau réseau bridge que l’on va appeler localnetwork :
docker network create -d bridge localnetworkL’option -d permet de spécifier le driver à utiliser.
Vérifions que celui-ci est bien créé à l’aide de la commande docker network ls :
docker network lsNETWORK ID NAME DRIVER SCOPE670c93095add bridge bridge localb254d4aba0cd host host localf420a065ce23 localnetwork bridge localf35bca9fc290 none null localVous remarquerez que Docker crée trois réseaux par défaut : bridge, none et host.
Créons ensuite un conteneur en mode interactif et connectons-le au réseau localnetwork :
docker container run -it --name container-1 --network localnetwork alpine shPour choisir à quel réseau le conteneur doit se connecter, nous utilisons l’option --network en spécifiant le nom du réseau.
Créons ensuite un deuxième conteneur également en mode interactif en le connectant également au réseau localnetwork :
docker container run -it --name container-2 --network localnetwork alpine shMaintenant depuis le premier conteneur, envoyons un ping vers le deuxième conteneur :
/ # ping container-2PING container-2 (172.19.0.3): 56 data bytes64 bytes from 172.19.0.3: seq=0 ttl=64 time=0.178 ms64 bytes from 172.19.0.3: seq=1 ttl=64 time=0.138 ms64 bytes from 172.19.0.3: seq=2 ttl=64 time=0.195 ms64 bytes from 172.19.0.3: seq=3 ttl=64 time=0.135 ms^C--- container-2 ping statistics ---4 packets transmitted, 4 packets received, 0% packet lossround-trip min/avg/max = 0.135/0.161/0.195 msLes conteneurs, faisant partie d’un même réseau, peuvent communiquer ensemble au travers de leurs noms. Tout cela est possible grâce au “service discovery”.
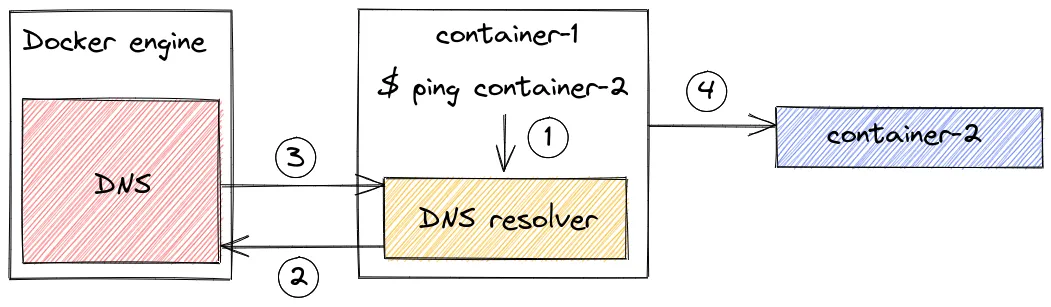
Voici le fonctionnement :
- La commande ping appelle le résolveur DNS local (chaque conteneur à un résolveur DNS) pour résoudre le nom
container-2en une adresse IP ; - Si l’adresse IP du nom
container-2ne se trouve pas dans le cache du résolveur, celui-ci la demande au serveur DNS de Docker ; - Le serveur DNS renvoie l’adresse IP de
container-2au résolveur DNS du conteneurcontainer-1. Cela fonctionne, car les deux conteneurs se trouvent dans le même réseau, j’insiste, mais c’est important, dans le cas contraire cela ne fonctionnerait pas ; - La commande ping peut maintenant envoyer la requête à l’adresse IP de
container-2.
Les principales commandes
Documentation officielle : https://docs.docker.com/engine/reference/commandline/network
Voyons maintenant les principales commandes concernant les réseaux.
Créer un réseau
Documentation officielle : https://docs.docker.com/engine/reference/commandline/network_create
docker network create [OPTIONS] NETWORKLister les réseaux
Documentation officielle : https://docs.docker.com/engine/reference/commandline/network_ls
docker network ls [OPTIONS]Supprimer un réseau
Documentation officielle : https://docs.docker.com/engine/reference/commandline/network_rm
docker network rm NETWORK [NETWORK...]Supprimer les réseaux inutilisés
Documentation officielle : https://docs.docker.com/engine/reference/commandline/network_prune
docker network prune [OPTIONS]Connecter un conteneur à un réseau
Documentation officielle : https://docs.docker.com/engine/reference/commandline/network_connect
docker network connect [OPTIONS] NETWORK CONTAINERDéconnecter un conteneur d’un réseau
Documentation officielle : https://docs.docker.com/engine/reference/commandline/network_disconnect
docker network disconnect [OPTIONS] NETWORK CONTAINERPour finir…
Cet article est déjà bien trop long, je vais donc m’arrêter là. Nous venons de voir les bases de Docker, mais il reste encore pas mal de choses à découvrir. Dans le prochain article, nous allons apprendre à conteneuriser notre propre application. En attendant, je vous invite à jouer un peu avec Docker en utilisant des images provenant du Docker hub, vous avez le choix il y a un peu près des images pour tout ! Prenez le temps de comprendre chaque commande et n’ayez pas peur de faire n’importe quoi, n’oubliez pas qu’un conteneur est isolé de la machine hôte.

Partage ta réflexion, pose une question ou laisse un retour.