
On a vu dans un précédent article, comment écrire ses messages de commits clairs et concis, mais cela ne suffit pas. Beaucoup de personnes, par simplicité, créées des commits contenant l’ensemble de leurs modifications. Pourtant procéder ainsi peut poser de nombreux soucis. C’est pourquoi il est souvent recommandé d’écrire des commits atomiques.
C’est quoi un commit atomique ?
Rien à voir avec la bombe atomique, quoique ne pas écrire de commit atomique pourrait avoir le même résultat sur votre projet… Non un commit est dit atomique si celui-ci respecte les trois règles suivantes :
- Celui-ci ne concerne qu’un seul et unique sujet. Par sujet je veux dire, une correction de bug, une fonctionnalité, une refactorisation, etc. ça vous rappelle sûrement le principe de responsabilité unique de SOLID ;
- Celui-ci ne doit pas rendre incohérent le dépôt, par exemple faire échouer des tests ou encore rendre impossible le build du projet ;
- Celui-ci doit avoir un message clair et concis (Bon ça normalement vous savez faire !).
Imaginons que j’ai une tâche qui consiste à ajouter une route sur une API permettant d’ajouter des commentaires, je pourrais avoir les commits suivant :
feat(models): add comment's data modelfeat(controllers): add comment's controllertest(controllers): add tests for the comment's controllerfeat(routes): add comment's routetest(routes): add tests for the comment's routefix(routes): add data checking in the comment's routedocs(routes): create swagger documentation for comment's routetest(controllers): add benchmarking for the comment's controllerperf(controllers): add cache for the comment's controllerOui ça fait beaucoup de commits, et alors ? Et encore ici c’est un exemple rapide pour illustrer l’article, j’aurais pu avoir beaucoup plus de commits. Beaucoup pensent à tort que créer trop de commits est une mauvaise pratique alors que c’est tout le contraire. Mais voyons voir pourquoi est-il important d’écrire des commits atomiques.
Mais d’où vient ce bug ?
Lorsque j’ai commencé ma carrière en tant que développeur, je faisais partie d’une équipe où les bonnes pratiques étaient le dernier de nos soucis, à vrai dire on ignorait même totalement les notions de bonnes pratiques, notre CTO n’y connaissait rien et la majorité de l’équipe était composée de juniors sortis de l’école qui voulaient simplement prouvaient qu’ils savaient coder rapidement et bien entendu j’en faisais parti. On avait là le cocktail parfait pour écrire du code tout droit sorti de l’enfer.
À l’époque, GIT était tout nouveau pour nous puisque jusqu’à maintenant on utilisait SVN, donc autant vous dire que l’utilisation de commits atomiques nous était totalement inconnue.
Un jour on a eu un bug sur la production, un bug incompréhensible, on avait passé plusieurs heures à comprendre comment le reproduire mais impossible de savoir d’où celui-ci provenait. Un de mes collègues avait lu un article sur la commande git bisect.
La commande git bisect permet d’effectuer une recherche dichotomique sur une liste de commits afin de trouver celui où le bug a été introduit. Son utilisation peut paraître compliquée au premier abord mais elle est assez simple.
Voyons un exemple pour illustrer son utilisation. Imaginons l’historique suivant :

Pour démarrer la recherche, il suffit d’utiliser la commande git bisect start et ensuite préciser via la commande git bisect bad, un commit connu comme étant problématique. Imaginons que c’est notre commit 010. Nous utilisons donc la commande git bisect bad 010 ou tout simplement git bisect bad qui utilise par défaut le commit pointé par HEAD.
Il faut ensuite, via la commande git bisect good, préciser un commit n’ayant pas de problème. Dans notre exemple, nous allons dire que c’est le commit 003, ce qui nous donne la commande suivante, git bisect good 003.
Donc pour résumer, nous devons lancer les trois commandes suivantes :
$ git bisect start$ git bisect bad$ git bisect good 003
Bisecting: 2 revisions left to test after this (roughly 2 steps)[007] feat: ...C’est parti, la recherche démarre ! Git va alors se positionner sur le commit du milieu de l’intervalle, dans notre cas il s’agit du commit 007, et va nous demander si le problème existe sur celui-ci. Si c’est le cas nous devons utiliser la commande git bisect bad et dans le cas contraire la commande git bisect good.
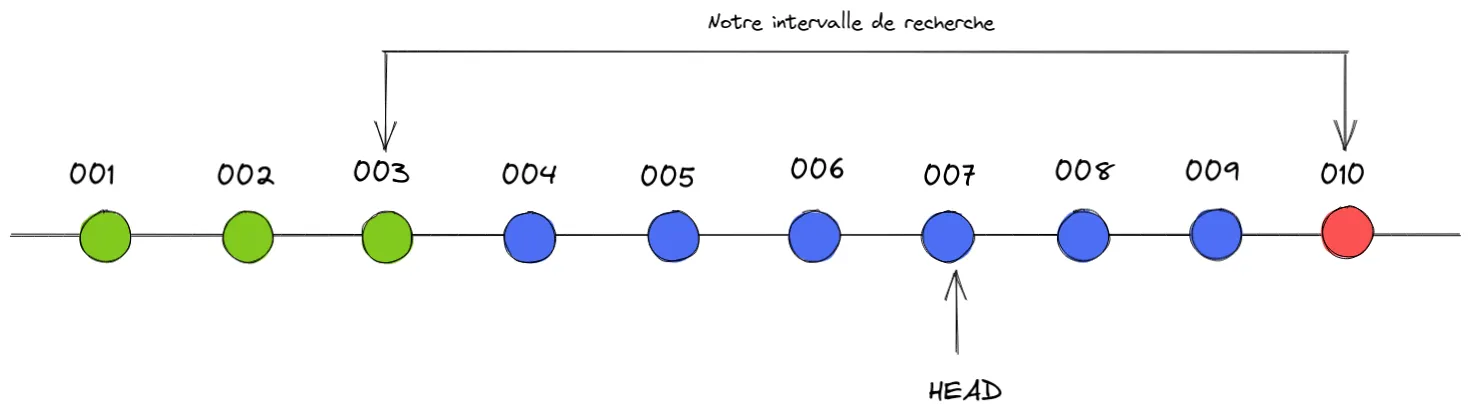
Nous allons considérer que le problème existe sur ce commit :
$ git bisect badBisecting: 1 revision left to test after this (roughly 1 step)[005] fix: ...Git poursuit ensuite sa recherche en réduisant l’intervalle et comme précédemment, il se positionne sur le commit du milieu, ici le 005, et nous redemande si le problème existe sur celui-ci.
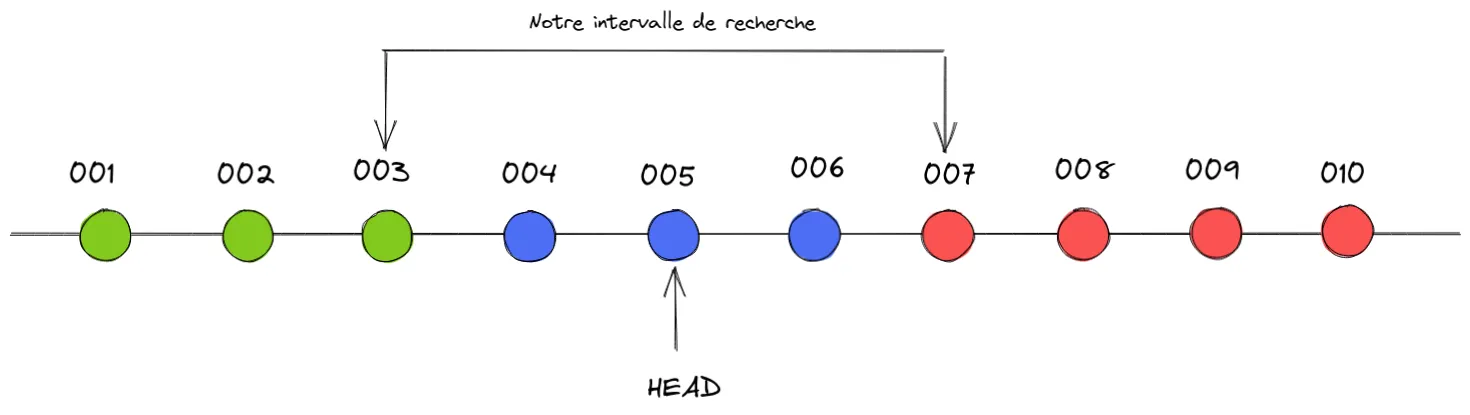
Nous allons considérer que le problème n’existe pas sur ce commit :
$ git bisect goodBisecting: 0 revisions left to test after this (roughly 0 steps)[006] chore:...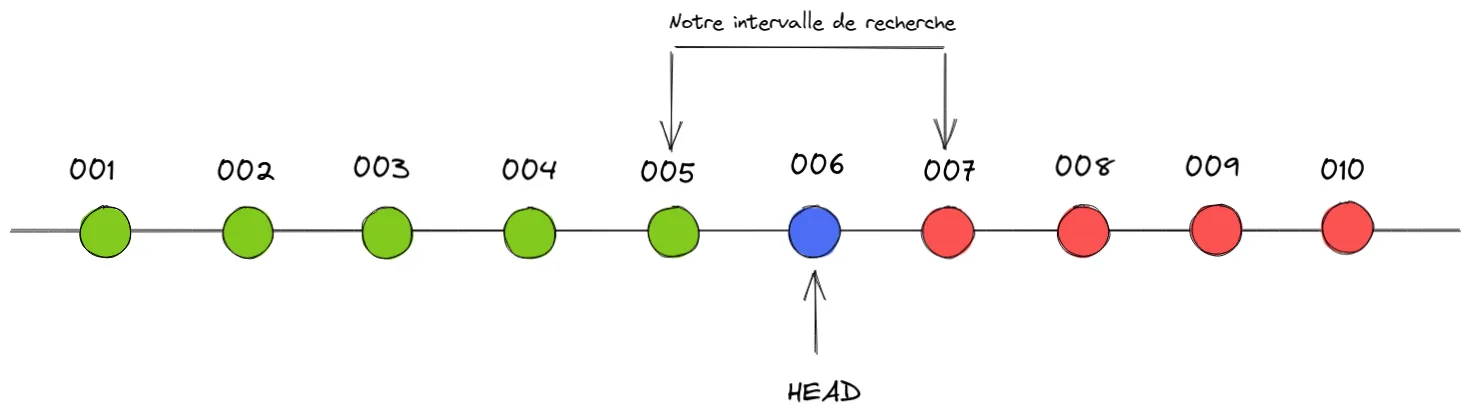
Nous avons presque terminé, nous devons maintenant indiqué si le commit 006 est problématique ou non. Si c’est le cas, ce sera donc l’origine de notre problème puisque le commit 007 est également problématique mais pas le commit 005. Par contre, si celui-ci n’est pas problématique ce sera le commit 007 qui sera l’origine du problème.
Pour notre exemple, indiquons que le commit 006 est problématique :
$ git bisect bad006 is the first bad commitcommit 006......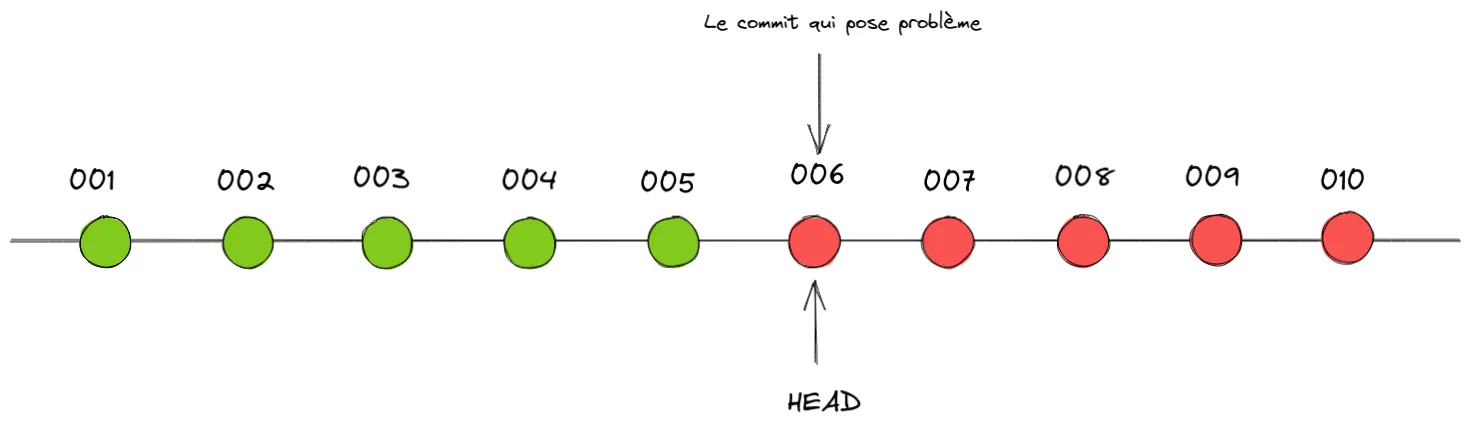
Et voilà nous avons pu trouver facilement dans quel commit le bug a été introduit. Nous pouvons ensuite quitter la recherche via la commande git bisect reset.
Sachez également que vous pouvez automatiser la recherche via un script qui teste votre code, si ça vous intéresse je ferai un petit article dessus.
Bref, revenons à mon anecdote. Avec mon collègue on commence donc à utiliser la commande git bisect et après quelques minutes on trouve enfin le commit qui pose problème. On souffle un peu, on est super content de nous, sauf que… vous le voyez venir ou pas ? Le commit était tellement énorme, il y avait tellement de changement qu’il était impossible de savoir d’où venait le problème facilement. Finalement après quelques heures de recherche, on a réussi à trouver le bug, celui-ci provenait d’une librairie externe suite à une mise à jour effectuée dans le commit en question.
Si on avait eu un commit atomique ne contenant que cette mise à jour de librairie on aurait tout de suite trouvé d’où provenait le problème.
Annuler un changement
L’avantage de Git et du versionning de manière générale est de pouvoir revenir en arrière en cas de soucis. Il peut arriver que l’on ait besoin d’annuler des changements dans notre code déjà publiés sur le dépôt, par exemple suite à la découverte d’un bug. Nous pouvons modifier notre code pour annuler ces changements mais cela n’est pas la meilleure façon de faire. Au lieu de ça, Git fournit la commande git revert permettant d’annuler les changements présents dans un commit en créant un nouveau commit contenant ces annulations.
Pour annuler un commit, il suffit d’utiliser la commande git revert de cette manière :
git revert <commit>Reprenons notre exemple d’historique :
Imaginons que nous souhaitons annuler les changements introduits dans le commit 006, pour cela nous utilisations la commande suivante :
git revert 006
Git ne supprime pas le commit de l’historique du projet mais en créer un nouveau en annulant les changements introduits par le commit. Cela permet de garder un historique de l’ensemble des modifications apportées au projet.
C’est bien beau tout ça mais quel est le rapport avec les commits atomiques ? Si le commit 006 n’est pas atomique et que l’on souhaite appliquer la commande git revert sur celui-ci, on risque d’annuler d’autres changements. Notre seule option est donc d’annuler les changements à la main et si ceux-ci sont particulièrement importants, cela va vite devenir pénible.
Au contraire si l’on avait écrit des commits atomiques, l’annulation des changements aurait pu être effectuée en quelques secondes.
Comprendre les changements
Que ce soit lors de la revue de code ou lors d’une recherche dans l’historique, il est primordial de comprendre les changements introduits par les différents commits. Si les changements sont regroupés dans un seul commit, il devient difficile de comprendre la logique concernant les changements.
Si je reprends l’exemple du début d’article, :
feat(models): add comment's data modelfeat(controllers): add comment's controllertest(controllers): add tests for the comment's controllerfeat(routes): add comment's routetest(routes): add tests for the comment's routefix(routes): add data checking in the comment's routedocs(routes): create swagger documentation for comment's routetest(controllers): add benchmarking for the comment's controllerperf(controllers): add cache for the comment's controllerEt que je remplace celui-ci par un seul commit :
feat: add comment's API routeOn perd les informations concernant les différents changements effectués.
Dans certaines équipes, il est possible que la politique de merge de branches est de combiner l’ensemble des commits en un seul (squash) comme ci-dessus. Je ne suis pas forcément fan de cette façon de faire mais cela ne vous empêche en rien de créer plusieurs commits.
Découper son travail en petites tâches
Dans l’exemple ci-dessus, le fait d’avoir plusieurs commits, nous permet de découper notre travail en plus petites tâches permettant de réduire notre charge mentale et donc faciliter le développement de la fonctionnalité. Un autre avantage est également de sauvegarder plus souvent notre travail et de ne pas attendre la fin de la tâche pour le faire.
Pour finir…
Même si cela peut sembler être une perte de temps, écrire des commits atomiques couplés à des messages clairs et concis, améliorera la qualité de votre travail et vous facilitera la vie ainsi que celle des autres développeurs de votre équipe. N’ayez donc pas peur d’écrire “trop” de commits lors de vos développements.



Partage ta réflexion, pose une question ou laisse un retour.