
Cela faisait longtemps que je n’avais pas fait un article sur les fonctionnalités du langage JavaScript. Le dernier en date concernait la métaprogrammation avec l’objet Proxy. Aujourd’hui, nous allons nous intéresser à deux concepts assez déroutants pour les débutants, j’ai nommé les itérateurs et les générateurs.
Les itérateurs
Vous avez tous déjà utilisé une boucle for..of pour parcourir les éléments d’un tableau ou encore utilisez l’opérateur de décomposition (spread operator) ...
const arr = [4, 8, 15, 16, 23, 42]
for (const value of arr) { console.log(value)}
console.log(...arr)
const str = 'Hello !'
for (const char of str) { console.log(char)}
console.log(...str)Mais savez-vous quel mécanisme se trouve derrière ses deux méthodes ? Je pense qu’au vu du titre vous vous en doutez un petit peu, il s’agit des itérateurs.
Qu’est-ce qu’un itérateur ?
Le concept d’itérateur a été introduit en 2015 lors de la sortie de version 6 d’EcmaScript, mais ce concept n’est pas nouveau puisqu’on le retrouve dans de nombreux langages comme Python, PHP ou encore C++. Un itérateur est tout simplement un objet permettant de parcourir une à une les données d’un autre objet dit itérable. Il s’agit en quelque sorte d’un pointeur permettant d’accéder à la valeur de l’élément pointé et pouvant se déplacer vers l’élément suivant de l’objet itérable.
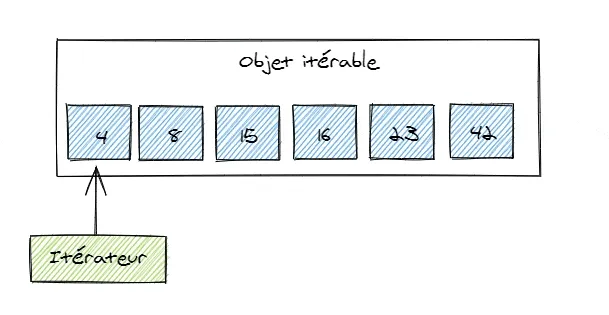
Les itérateurs et les objets itérables forment ce qu’on appelle le protocole d’itération.
Le protocole d’itération
Le protocole d’itération permet de standardiser la façon dont les sources de données peuvent être parcourues. Celui-ci repose sur deux interfaces (oui, je sais que les interfaces n’existent pas en JS, mais c’est pour faciliter la compréhension. Au pire les interfaces existent bel et bien en TypeScript) :
IterableIterator
Iterable
interface Iterable { [Symbol.iterator]() : Iterator;}L’interface Iterable exige qu’un objet implémente une méthode ayant comme clé Symbol.iterator et que celle-ci retourne un objet implémentant l’interface Iterator. Un objet itérable est donc simplement un objet implémentant cette interface.
Iterator
interface Iterator { next() : IteratorResult;}
interface IteratorResult { value: any; done: boolean;}L’interface Iterator exige, quant à elle, qu’un objet implémente une méthode next retournant un objet ayant les propriétés suivantes :
done: un booléen indiquant si l’itération est terminée ou non ;value: La valeur de l’élément courant.
Les appels à la méthode next permettent donc de parcourir un à un les éléments d’un objet.
Quelques objets itérables
JavaScript fournit nativement des objets implémentant l’interface Iterable :
- Les tableaux (
Array) ; - Les chaînes de caractères (
string) ; - Les dictionnaires (
Map) ; - Les ensembles (
Set) ; - Les objets DOM (
[NodeList](https://developer.mozilla.org/fr/docs/Web/API/NodeList "Les objets NodeList sont des collections de nœuds comme celles retournées par Node.childNodes et la méthode document.querySelectorAll().")).
Il est donc possible d’accéder à l’itérateur de ses objets via la méthode Symbol.iterator. Par exemple, pour un tableau :
const arr = [4, 8, 15, 16, 23, 42]
const iterator = arr[Symbol.iterator]()
console.log(iterator.next()) // { value: 4, done: false }console.log(iterator.next()) // { value: 8, done: false }console.log(iterator.next()) // { value: 15, done: false }console.log(iterator.next()) // { value: 16, done: false }console.log(iterator.next()) // { value: 23, done: false }console.log(iterator.next()) // { value: 42, done: false }console.log(iterator.next()) // { value: undefined, done: true } -> On a atteint la fin du tableauLa boucle for..of, l’opérateur de décomposition (spread operator) ou encore la méthode Array.from “consomment” des objets itérables et font donc appel à la méthode Symbol.iterator pour accéder à chaque élément.
Implémenter un objet itérable
Voyons maintenant comment implémenter un objet itérable. Prenons un exemple simple en créant un objet représentant un intervalle de nombre :
const range = { start: 0, stop: 10}Nous souhaitons maintenant parcourir chaque nombre compris entre la propriété start et stop via la boucle for..of. Pour cela implémentons la méthode Symbol.iterator :
const range = { start: 0, stop: 10, [Symbol.iterator] () { // On crée notre objet Iterator... const iterator = { current: this.start, end: this.stop, // Celui-ci implémente une méthode next... next () { // Qui retourne un objet {done: ..., value :...} if (this.current <= this.end) { return { done: false, value: this.current++ } } else { return { done: true } } } }
return iterator }}
for (let value of range) { console.log(value) // 1, 2, 3, 4, 5, 6, 7, 8, 9, 10}Cet exemple peut-être simplifié en déplaçant la fonction next dans l’objet range comme ceci :
const range = { start: 0, stop: 10, [Symbol.iterator] () { this.current = this.start return this }, next () { if (this.current <= this.stop) { return { done: false, value: this.current++ } } else { return { done: true } } }}
for (let value of range) { console.log(value) // 1, 2, 3, 4, 5, 6, 7, 8, 9, 10}Nous pouvons également créer des fonctions retournant des objets itérables. Si l’on reprend notre exemple précédent, il est possible d’implémenter une fonction similaire à la fonction range que l’on retrouve en Python :
function range (start, stop, step = 1) { let current = start return { [Symbol.iterator] () { return this }, next () { if (current <= stop) { const result = { done: false, value: current } current += step return result } else { return { done: true } } } }}
for (let value of range(0, 10, 2)) { console.log(value) // 0, 2, 4, 6, 8, 10}
const arr = Array.from(range(0, 5))console.log(arr) // [ 0, 1, 2, 3, 4, 5 ]
console.log(...range(5, 10)) // 5, 6, 7, 8, 9, 10La méthode return
Bon, je ne vous ai pas tout dit, mais un itérateur peut avoir une méthode optionnelle return en plus de la méthode next. Cette méthode est appelée lorsque l’itération prend fin prématurément, c’est notamment le cas lors de l’utilisation des instructions suivante :
break;continue;throw;return.
Vous allez me dire, mais à quoi cela peut-il servir ? Je vais vous donner un exemple très simple qui illustre parfaitement son utilisation. Imaginons que nous ayons une fonction permettant de lire ligne par ligne un fichier en utilisant un itérateur :
function readLine (fileName) { const file = open(fileName)
return { [Symbol.iterator] () { return this }, next () { if (file.readIsDone()) { file.close() return { done: true } } else { // Traitement synchrone du fichier... } } }}J’ai simplifié le code, mais c’est pour que vous compreniez. Maintenant pour x raisons, nous ajoutons un break dans une boucle for..of :
for (const line of readLine(fileName)) { console.log(line) break}Le break a pour effet de quitter la boucle sans que l’itération ne soit terminée, c’est-à-dire que la méthode next renvoie l’objet { done: true }, mais surtout, sans que l’appel à la fonction close de notre fichier soit effectué. On se retrouve donc là avec une potentielle fuite mémoire, car le descripteur de fichier n’est pas fermé.
Pour remédier à ce problème, il faut implémenter la méthode return pour fermer le fichier et indiquer que l’itération est terminée :
function readLine (fileName) { const file = open(fileName)
return { [Symbol.iterator] () { return this }, next () { if (file.readIsDone()) { file.close() return { done: true } } else { // Traitement synchrone du fichier... } }, return () { file.close() return { done: true } } }}
for (const line of readLine(fileName)) { console.log(line) break}Les itérateurs asynchrones
Nous venons de voir qu’il était possible de créer un objet itérable à l’aide d’un itérateur en implémentant la méthode Symbol.iterator. Il arrive cependant que les valeurs retournées par l’itérateur soient des promesses. Dans ce cas, nous pouvons créer un itérateur pour notre objet itérable à l’aide de la méthode Symbol.asyncIterator. Il suffit ensuite de consommer ses données asynchrones à l’aide de la méthode for await..of.
Imaginons que l’on souhaite récupérer des images aléatoires sur une API. Nous pouvons donc écrire une fonction utilisant un itérateur asynchrone et l’utiliser dans une boucle for await..of:
const axios = require('axios')
function randomImageIterator (total) { const url = 'https://picsum.photos/200/300' let count = 0 return { [Symbol.asyncIterator] () { return { async next () { // On Vérifie que l'on a pas atteint le total if (count >= total) { return { done: true } }
// On récupère l'image sur l'API const { data } = await axios.get(url, { responseType: 'arraybuffer' })
// On incrémente notre compteur d'image count++
// Et on renvoie notre résultat d'itération return { done: false, value: Buffer.from(data, 'binary').toString('base64') } } } } }}
(async () => { // On récupère toutes les images une à une ... for await (const base64Image of randomImageIterator(10)) { // Traitement de l'image... }})()Node.js utilise également les itérateurs asynchrones pour faciliter le traitement des streams :
const fs = require('fs')
const readable = fs.createReadStream('test.txt', { encoding: 'utf8' })
for await (const chunk of readable) { console.log(chunk)}Maintenant que vous savez ce qu’est un itérateur, il est temps de passer aux choses sérieuses et de parler des générateurs.
Les générateurs
Les générateurs sont l’une des fonctionnalités de JavaScript extrêmement puissantes, mais qui fait peur à la plupart des développeurs par leur fonctionnement quelque peu déroutant.
Qu’est-ce qu’un générateur ?
Un générateur ou generator est une fonction un peu spéciale pouvant retourner plusieurs valeurs et dont l’exécution peut être interrompue et repris plus tard. C’est un peu obscur, mais vous allez vite comprendre.
Un générateur est défini à l’aide du mot-clé function* et utilise le mot-clé yield pour retourner la valeur qui le succède avant de mettre en pause l’exécution de la fonction :
function * simpleGenerator () { yield 'a' yield 'b' return 'c'}
console.log(simpleGenerator()) // [object Generator]Lorsque l’on appelle notre fonction on remarque que le corps de celle-ci n’est pas été exécuté et qu’elle nous renvoie un objet Generator. Cet objet Generator, implémente à la fois l’interface Iterable et l’interface Iterator et nous permet de contrôler l’exécution de notre fonction.
À ce stade, notre fonction est mise en pause. Pour reprendre son exécution, nous devons utiliser la méthode next de l’objet Generator. La méthode next relance l’exécution de la fonction jusqu’à l’expression yield la plus proche et retourne la valeur qui succède celle-ci avant de remettre en pause l’exécution :
const generator = simpleGenerator()console.log(generator.next()) // { value: 'a', done: false }console.log(generator.next()) // { value: 'b', done: false }console.log(generator.next()) // { value: 'c', done: true }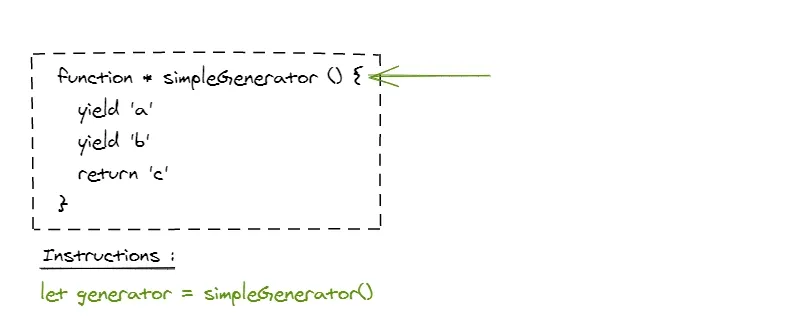
La valeur retournée par la méthode next est un objet ayant les propriétés suivantes :
done: un booléen indiquant si l’exécution est terminée ou non ;value: La valeur retournée par l’expressionyield(oureturn).
Rien d’étonnant puisque comme nous l’avons vu, un objet Generator implémente l’interface Iterator.
Si lors de l’appel à la méthode next, il n’existe plus aucune expression yield alors l’exécution de la fonction reprend jusqu’à sa terminaison. Si une instruction return est rencontrée, la valeur est retournée par la méthode next et la fonction est bien entendu terminée.
Cas d’utilisations
Il existe trois façons d’utiliser les générateurs :
- En tant que producteur de données (pull) ;
- En tant que consommateur de données (push) ;
- En tant que producteur et consommateur de données (coroutine).
Producteur de données (pull)
Le premier cas d’utilisation d’un générateur est la production de données, on nomme généralement ce mode fonctionnement “pull”. Dans ce cas, le générateur se comporte comme un itérateur. C’est ce que nous avons vu dans notre précédent exemple :
function * simpleGenerator () { yield 'a' yield 'b' return 'c'}
for (let value of simpleGenerator()) { console.log(value) // a b}
console.log(...simpleGenerator()) // a bVous remarquerez que la valeur renvoyée par l’instruction return n’est pas présente. Si la propriété done de l’objet retourné par next est égale à true alors la valeur contenue dans cet objet (value) est ignorée par les consommateurs d’objets itérable tel que for..of, l’opérateur de décomposition ou encore la méthode Array.from.
Simplifier l’écriture d’un itérateur
Les générateurs permettent de simplifier l’écriture des itérateurs. Prenons l’exemple d’une liste chaînée et écrivons dans un premier temps un itérateur pour parcourir chacun des nœuds de celle-ci en implémentant la méthode Symbol.iterator et rendre ainsi nos objets LinkedList itérables :
class LinkedList { constructor () { this.head = null this.tail = null }
append (value) { //... Ajoute un nœud à la fin }
[Symbol.iterator] () { let currentNode = this.head return { next () { if (currentNode !== null) { const result = { done: false, value: currentNode } currentNode = currentNode.next return result } else { return { done: true } } } } }}
const linkedList = new LinkedList()
linkedList.append(1).append(2).append(3).append(4).append(5)
for (let node of linkedList) { console.log(node.value) // 1 2 3 4 5}L’écriture d’un itérateur est tout de même lourde. Simplifions la méthode Symbol.iterator à l’aide d’un générateur :
class LinkedList { constructor () { this.head = null this.tail = null }
append (value) { //... Ajoute un nœud à la fin }
* [Symbol.iterator] () { let currentNode = this.head while (currentNode !== null) { yield currentNode currentNode = currentNode.next } }}
const linkedList = new LinkedList()
linkedList .append(1) .append(2) .append(3) .append(4) .append(5)
for (let node of linkedList) { console.log(node.value) // 1 2 3 4 5}Il n’y a pas photos, ça rend le code beaucoup plus clair.
Nous pouvons également réécrire la fonction range vu un peu plus tôt sous forme d’un générateur :
function * range (start, stop, step = 1) { let current = start while (current <= stop) { yield current current += step }}
for (let value of range(0, 10, 2)) { console.log(value) // 0, 2, 4, 6, 8, 10}
const arr = Array.from(range(0, 5))console.log(arr) // [ 0, 1, 2, 3, 4, 5 ]
console.log(...range(5, 10)) // 5, 6, 7, 8, 9, 10Ainsi que notre fonction permettant de récupérer des images aléatoires sur une API :
const axios = require('axios')
async function * randomImageIterator (total) { const url = 'https://picsum.photos/200/300' let count = 0 while (count < total) { const { data } = await axios.get(url, { responseType: 'arraybuffer', })
yield Buffer.from(data, 'binary').toString('base64') // On incrémente notre compteur d'image count++ }
}
(async () => { // On récupère toutes les images une à une ... for await (let base64Image of randomImageIterator(10)) { // Traitement de l'image... }
// Ou à la demande const iterator = randomImageIterator(10) // retourne un objet AsyncGenerator let { value: base64Image } = await iterator.next()})()Séquence de données infinie
Un générateur peut également produire une séquence de données infinie :
function * infiniteGenerator () { let counter = 0 while (true) { yield counter++ }}Pour restreindre le nombre d’itérations, vous pouvez utiliser la fonction take suivante :
function * take (n, iterable) { let counter = 0 for (const value of iterable) { if (counter === n) { return } counter++ yield value }}
// On limite l'itération à deux élémentsfor (let id of take(2, infiniteGenerator())) { console.log(id)}Attention tout de même avec l’utilisation de cette fonction take, car celle-ci met fin prématurément à l’itération du générateur via l’instruction return quand le compteur a atteint le nombre d’itérations voulu. Il peut, dans certains cas, être nécessaire d’effectuer certaines actions avant la fermeture du générateur. Pour cela il suffit d’ajouter un bloc finally et d’y effectuer les actions voulues.
function * cleanupGenerator () { try { // Votre code... } finally { // Les tâches à effectuer à la fin du générateur ou en cas de fermeture prématurée }}
for (let value of take(2, cleanupGenerator())) { // ...}Délégation via yield*
Imaginons maintenant que nous souhaitons extraire tous les liens contenus dans l’objet suivant :
const posts = { title: 'Profiler son application Node.js : analyse de la mémoire', url: 'https://tinyurl.com/2dn8k2s6', links: [ { title: 'Profiler son application Node.js : analyse des performances CPU', url: 'https://tinyurl.com/jkyyahxj', links: [ { title: 'Démystifions la boucle d’événement (event loop) de Node.js', url: 'https://tinyurl.com/jkyyahxj', links: [], }, { title: 'Sécuriser une API REST (3/3) : gestion du JWT coté client', url: 'https://tinyurl.com/1bxuhwdq', links: [], }, ], }, ],}Nous pouvons pour cela écrire un générateur utilisant la récursivité :
function * extractURL (data) { yield data.url if (data.links) { for (let link of data.links) { yield * extractURL(link) } }}
for (let url of extractURL(posts)) { console.log(url)}L’expression yield* permet simplement de déléguer l’exécution à un autre générateur qui va itérer sur ses valeurs et retourner celles-ci au générateur qui l’appelle. Cette expression fonctionne également sur n’importe quel objet itérable :
function * generatorWithArray () { yield * [1, 2, 3, 4, 5]}
for (let value of generatorWithArray()) { console.log(value)}Réduction de la consommation mémoire
L’un des principaux avantages des générateurs est que ceux-ci sont exécutés uniquement quand on en a besoin (lazy evaluation) ce qui permet d’améliorer les performances et de réduire la consommation mémoire.
Voyons un autre exemple concret. Imaginons que l’on souhaite extraire d’un tableau d’entiers les valeurs paires, les multiplier par deux puis ajouter 5 à celles-ci. Naïvement, nous pourrions écrire le code suivant :
function even (nums) { const result = [] for (let num of nums) { if (num % 2 === 0) { result.push(num) } } return result}
function multiplyByTwo (nums) { const result = [] for (let num of nums) { result.push(num * 2) } return result}
function addFive (nums) { const result = [] for (let num of nums) { result.push(num + 5)
} return result}
function pipeline (...iterables) { return iterables.reduce((acc, cur) => cur(acc))}
for (let value of pipeline([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], even, multiplyByTwo, addFive)) { console.log(value)}Le problème de cette approche est que nous sommes contraints d’allouer un tableau dans chaque fonction et de générer l’ensemble des valeurs avant de passer à la fonction suivante. Si la taille du tableau est importante nous allons donc consommer de la mémoire inutilement. De plus, nous n’avons pas réellement un fonctionnement sous forme de pipeline.
Une seconde approche consiste à utiliser des générateurs :
function * even (nums) { for (let num of nums) { if (num % 2 === 0) { yield num } }}
function * multiplyByTwo (nums) { for (let num of nums) { yield num * 2 }}
function * addFive (nums) { for (let num of nums) { yield num + 5 }}
function pipeline (...iterables) { return iterables.reduce((acc, cur) => cur(acc))}
for (let value of pipeline([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], even, multiplyByTwo, addFive)) { console.log(value)}Cette fois-ci nous avons bien un fonctionnement sous forme de pipeline, c’est-à-dire que chaque valeur renvoyée par un générateur est transférée au générateur suivant avant de produire la valeur suivante. Il n’est également plus nécessaire de stocker toutes les valeurs dans un tableau.
En bonus, je vous montre comment réécrire cet exemple avec des méthodes plus génériques :
function map (fn) { return function * (iterable) { for (const value of iterable) { yield fn(value) } }}
function filter (predicate) { return function * (iterable) { for (const value of iterable) { if (predicate(value)) { yield value } } }}
const numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]const values = pipeline( numbers, filter(val => val % 2 === 0), map(val => val * 2), map(val => val + 5))
for (let value of values) { console.log(value)}Si vous voulez une solution encore plus élégante, j’ai crée ce dépôt GitHub.
Un exemple réel
Je vais vous donner un exemple réel d’utilisation des générateurs qui m’a permis d’améliorer les performances et de réduire la consommation mémoire de mon code.
Je devais, pour les besoins d’un projet, “scrapper” une page web, c’est-à-dire collecter des informations contenues dans celle-ci, puis d’effectuer par la suite différents traitements sur chacune des données extraites.
La quantité de données étant très importante, j’ai vite été confronté à un souci de performance et à une explosion de la consommation mémoire puisque je devais dans un premier temps extraire toutes les données et dans un second temps appliquer les différents traitements dessus.
J’ai donc utilisé des générateurs, ce qui m’a permis d’extraire une par une les données et de pouvoir appliquer sans attendre les différents traitements sur celles-ci. De plus, je n’étais pas obligé d’extraire la totalité des données, puisque j’avais la main sur l’exécution et je pouvais mettre fin à mon extraction à tout moment. Un autre avantage est que cela me permettait de découpler facilement mon code qui concerne l’extraction de celui qui concerne les traitements.
Consommateur de données (push)
Les générateurs peuvent également consommer des données, on nomme généralement ce mode de fonctionnement “push”. En plus des interfaces Iterable et Iterator, les générateurs implémentent l’interface Observer que voici :
interface Observer { next(value? : any) : void; return(value? : any) : void; throw(error) : void;}- La méthode
nextpermet d’envoyer une valeur au générateur ; - La méthode
returnpermet de clôturer le générateur ; - La méthode
throwpermet de lever une exception au sein du générateur.
Ce mode de fonctionnement ressemble beaucoup à RxJS que je vous invite à aller voir si vous voulez en savoir plus.
La méthode next
Nous avons déjà vu que la méthode next permettait de retourner les données qui succèdent les expressions yield, mais il est également possible de transmettre des données via cette même méthode. Voyons un petit exemple :
function * printSumGenerator () { const a = yield const b = yield
console.log(a + b)}
const generator = printSumGenerator()
gen.next() // Exécute le générateur et s'arrête au prochain yieldgen.next(10) // Remplace le premier yield par 10gen.next(5) // Remplace le second yield par 5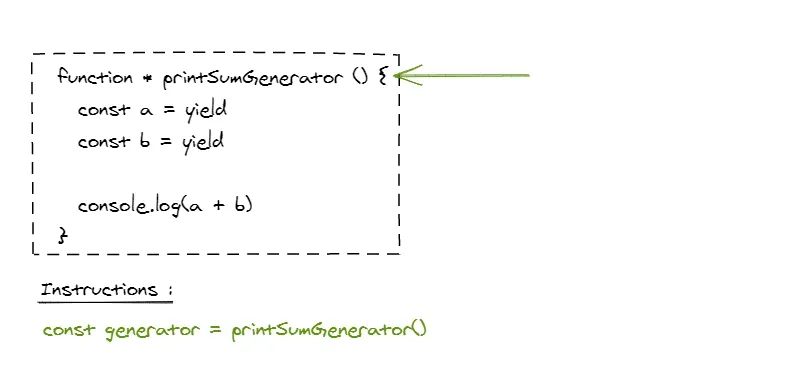
On remarque que le premier appel à la méthode next, permet uniquement d’exécuter le générateur et de l’arrêter à la prochaine expression yield. C’est donc à partir du second appel à la méthode next qu’il est possible de transmettre des valeurs qui remplacent les expressions yield.
La méthode return
L’appel à la méthode return permet de mettre fin (prématurément) à un générateur et donc d’exécuter le code présent dans le bloc finally lorsque celui-ci est présent :
function * printSumGenerator () { try { const a = yield const b = yield console.log(a + b) } finally { console.log('cleanup') }}
const generator = printSumGenerator()generator.next(10)generator.return() // cleanupLa méthode throw
La méthode throw permet quant à elle de lever une exception au sein d’un générateur et d’exécuter le bloc catch et finally lorsqu’ils sont présents :
function * printSumGenerator () { try { const a = yield const b = yield console.log(a + b) } catch (err) { console.log(err) } finally { console.log('cleanup') }}
const generator = printSumGenerator()generator.next(10)generator.throw(new Error('Invalid value !'))Consommateur et producteur de données (coroutine)
Le dernier cas d’utilisation est sûrement l’un des plus puissants, il s’agit d’utiliser les générateurs à la fois comme consommateur et producteur de données, on parle parfois de coroutine. Cela est possible via la méthode next qui permet à la fois de récupérer des données d’un générateur, mais également de lui en transmettre. Voyons sans plus tarder quelques exemples d’utilisations.
Traitement des promises
Si comme moi vous avez utilisé les promesses bien avant l’arrivée des mots-clés async/await, vous êtes sûrement déjà tombés sur ce genre de code :
function asyncFn (value, delayInMs) { return new Promise(resolve => setTimeout(() => resolve(value), delayInMs))}
runner(function * () { try { const hello = yield asyncFn('Hello', 1000) const world = yield asyncFn('World !', 2000) console.log(`${hello} ${world}`) } catch (error) { console.log(error) }})()Ça ressemble à s’y m’éprendre à une fonction async à la différence qu’on utilise un générateur et l’expression yield à la place de await. Toute la magie se passe dans la fonction runner, celle-ci prend en paramètre un générateur et traite les promesses de façon à ce que le résultat de celles-ci soit retourné au générateur. Voyons un peu le code de cette fonction runner :
function runner (generatorFunc) { return function (...args) { const it = generatorFunc.apply(this, args)
// La fonction run sera exécutée récursivement une fois que la promesse en cours sera résolue function run (arg) { // On récupère la promise (value) ainsi que l'état de notre générateur (done) // On passe également à la méthode next le résultat de la précédente promesse const { value, done } = it.next(arg)
if (done) { return Promise.resolve(value) } else { // On "wrap" value dans une promesse dans le cas où celle-ci n'en était pas une // puis une fois la promesse résolue, on appelle récursivement run avec le résultat // de la promesse qui sera transmise au générateur (via it.next(arg)) // Si une erreur se produit, on transmet celle-ci au générateur return Promise.resolve(value).then(run, (error) => it.throw(error)) } }
return run() }}Utiliser les générateurs pour traiter les promesses permet d’avoir beaucoup plus de contrôle sur le flow asynchrone. Vous pouvez par exemple le stopper quand vous le souhaitez. Si cela vous intéresse, vous pouvez jeter un coup d’œil à la librairie CAF (Cancelable Async Flows).
Gérer des tâches concurrentes
Imaginons une partie de ping-pong, chaque joueur doit attendre que l’autre joueur envoie la balle pour pouvoir à son tour jouer. C’est exactement le même principe avec des taches concurrentes, certaines doivent attendre que d’autres aient terminé avant de pouvoir poursuivre leurs exécutions. Elles peuvent également avoir besoin d’information venant d’autres taches. Mais comment connecter, synchroniser et faire communiquer des tâches concurrentes entre elles ?
Certains langages comme Go utilisent le modèle CSP (Communicating sequential processes) pour résoudre ces problèmes. L’idée est simplement d’utiliser des canaux (channel) de communication permettant de connecter, synchroniser et faire communiquer des tâches concurrentes entre elles.
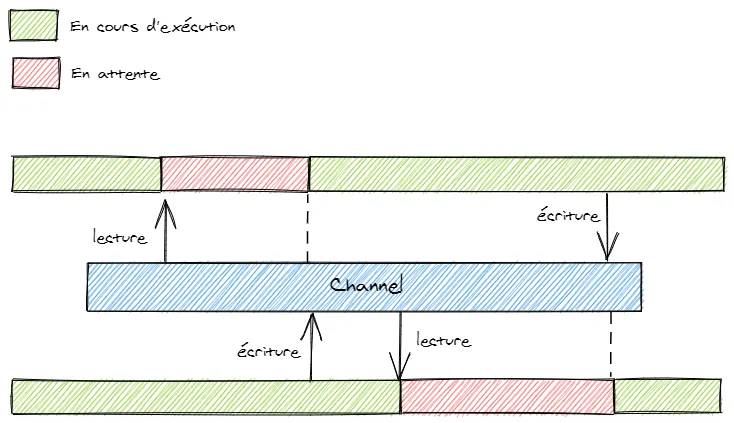
Il est possible d’utiliser le même mécanisme en JavaScript à l’aide des générateurs via notamment la librairie js-csp. Commençons par installer celle-ci :
npm install js-cspPuis écrivons l’exemple d’une partie de ping-pong :
const csp = require('js-csp')
function * player (name, table) { while (true) { // On attend la balle let ball = yield csp.take(table)
// Si le canal est fermé on arrête notre fonction via l'instruction return if (ball === csp.CLOSED) { console.log(name + ': table\'s gone') return }
// On incrémente le nombre de coup ball.hits += 1 console.log(`${name} ${ball.hits}`)
// On attent 100 ms ... yield csp.timeout(100) // Et on renvoie la balle à l'autre joueur via le canal yield csp.put(table, ball) }}
csp.go(function * () { // On créer notre canal const table = csp.chan()
// On exécute nos deux générateurs qui représentent nos deux joueurs csp.go(player, ['ping', table]) csp.go(player, ['pong', table])
// Comme notre premier joueur (ping) et en attente de la balle (via l'instuction take) // nous devons "mettre la balle" sur la table, c'est-à-dire écrire dans le canal via put yield csp.put(table, { hits: 0 })
// On attend 1 seconde yield csp.timeout(1000)
// Et on ferme notre canal (oui la partie était rapide :p) table.close()})Comme vous pouvez le voir c’est très simple d’utilisation et une fois le concept maîtrisé cela permet de gérer très facilement des flows asynchrones qui peuvent s’avérer de prime abord complexes. Les développeurs React ont sûrement déjà utilisé ce principe via la librairie redux-saga qui permet très facilement d’effectuer des tâches asynchrones et de découpler la logique métier de ses vues.
Bonus : Pour celles et ceux que ça intéresse, j’ai écrit une petite librairie toute simple qui implémente CSP, mais cette fois-ci uniquement avec des promesses : https://github.com/arkerone/csp-promise
Pour finir…
Je pourrais encore parler pendant des heures des itérateurs et des générateurs tellement leur utilisation est passionnante et extrêmement puissante, mais l’article est déjà bien trop long donc je vais m’arrêter là.
Vous devriez maintenant avoir une bonne vision des différents cas d’utilisations des itérateurs et des générateurs et vous n’avez plus aucune excuse pour ne pas les utiliser.
Si vous souhaitez un peu approfondir le sujet, je vous conseille l’article dédié aux itérateurs et celui dédié aux générateurs sur l’excellent site exploringjs.com.



Partage ta réflexion, pose une question ou laisse un retour.