
On se retrouve aujourd’hui pour le premier article d’une série consacré à l’analyse des performances des applications Node.js. Pour ce premier article, nous allons nous intéresser à l’analyse des performances CPU et voir comment optimiser celles-ci.
Cette série se compose de quatre articles :
- Analyse des performances CPU;
- Analyse de la mémoire;
- Analyse des traitements asynchrones;
- Un profiler pensé pour les agents IA.
Comme toujours, le code présenté dans mes articles est fonctionnel, mais simplifié pour se concentrer uniquement sur les concepts clés. Dans le cas de cet article, vous apprendre à utiliser les outils d’analyse de performance.
Comment fonctionne Node.js ?
Avant de commencer à parler d’optimisation, il est bon de rappeler comment fonctionne Node.js.
Node.js contrairement à d’autres plateformes, est monothreadé, bien que ce ne soit plus vraiment exact depuis la version 10 avec l’arrivée des worker threads. Ce mode de fonctionnement implique que Node.js ne peut exécuter qu’une seule tâche à la fois, ce qui au premier abord peut paraître peu efficace, mais Node.js tire sa force de son architecture événementielle et asynchrone basée sur le design pattern “Reactor”.
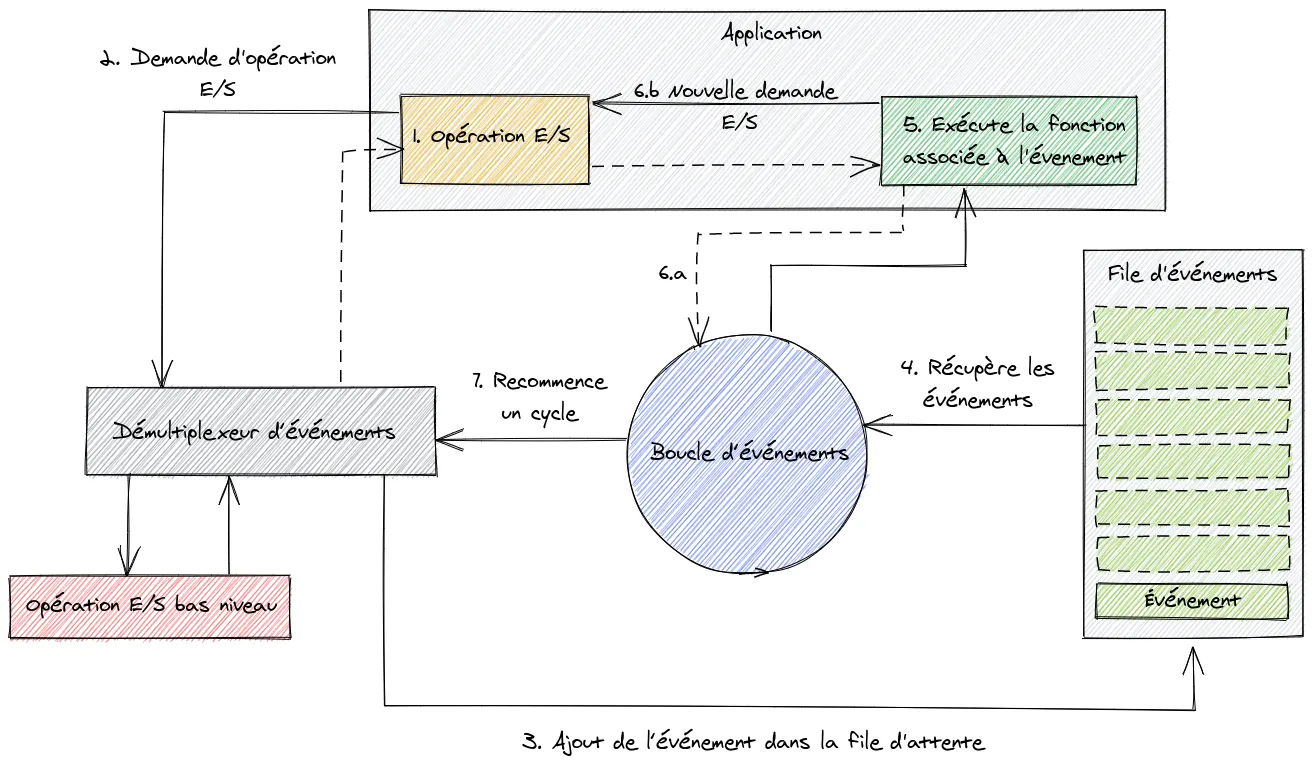
Voici une vue macro de son fonctionnement :
- L’application souhaite effectuer une opération d’entrée/sortie (lecture d’un fichier, requête réseau, etc.);
- L’application effectue une demande d’opération à un démultiplexeur d’événements chargé de faire appel à des fonctions bas niveaux. L’application spécifie également une fonction qui sera appelée à la fin de l’opération (handler). Cette demande faite au démultiplexeur est non bloquante, le contrôle est rendu à l’application;
- Une fois l’opération terminée, le démultiplexeur ajoute un événement dans la file d’événements;
- La boucle d’événement récupère l’ensemble des événements de la file;
- Pour chaque événement, la fonction associée est exécutée au sein de l’application;
- Une fois la fonction associée à l’événement terminée, le contrôle est redonné à la boucle d’événements (6.a). Par contre, si une nouvelle demande d’opération d’entrée/sortie est faite (6.b) dans la fonction associée à l’événement, cela provoque une nouvelle demande au démultiplexeur d’événement avant de redonner le contrôle à la boucle d’événement (6.a);
- Lorsque tous les événements de la file ont été traités, la boucle d’événement attend que le démultiplexeur d’événements recommence un nouveau cycle.
Si vous souhaitez plus de détails sur ce fonctionnement, je vous invite à aller jeter un coup d’œil à l’article sur la boucle d’événements.
Lorsque l’on développe une application Node.js, il faut donc être prudent à ne pas bloquer la boucle d’événements par des traitements trop coûteux en temps CPU. Si l’on reprend le schéma plus haut, tant que l’exécution de la fonction associée à l’événement (en 5) n’est pas terminée, la boucle d’événement est bloquée, ce qui peut être catastrophique pour les performances de votre application.
Optimisations des performances
On devrait oublier les petites optimisations locales, disons, 97 % du temps : l’optimisation prématurée est la source de tous les maux.
Donald Knuth
Avant de commencer, je vais vous raconter une petite anecdote. Je bossais il y a quelques années sur un projet qui avait une deadline assez courte et non extensible. On était plusieurs à bosser sur ce projet, j’étais l’un des deux développeurs backend. Le second était le lead developer, celui-ci voulait à tout prix optimiser les performances : réduire les temps de réponse, trouver les meilleurs algorithmes, etc. Dès qu’il écrivait une fonction, il cherchait à l’optimiser. Bref pour faire court on n’a pas pu terminer à temps le projet et l’on a perdu le contrat avec le client. Le pire dans cette histoire c’est que c’était un POC, les performances c’était le dernier de nos soucis.
Make it work, Make it right, Make it fast
Kent Beck
La morale de l’histoire c’est qu’avant de chercher à optimiser un programme, il faut d’abord que celui-ci fonctionne et soit bien conçu.
Une fois que notre programme fonctionne et répond aux besoins, il peut arriver que celui-ci ait des problèmes de performances, c’est à ce moment-là que l’on peut commencer à analyser les performances et tenter de les améliorer.
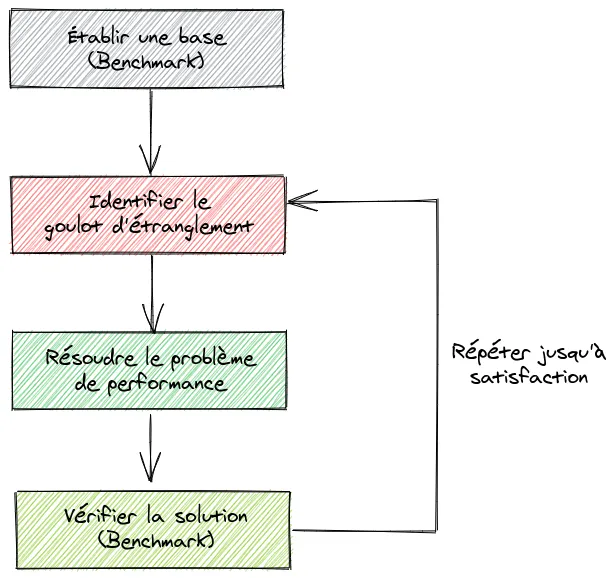
Le processus d’optimisation d’une application comporte 4 étapes :
- Établir une base : Avant de commencer, il est nécessaire d’établir les performances actuelles de l’application à l’aide d’un test de performance (Benchmark). Ce sera le point de départ de notre processus d’optimisation. Nous pouvons ensuite définir un objectif, par exemple dans le cas d’une API REST, le temps de latence moyen à atteindre ou le nombre de requêtes à la seconde qu’il est possible de traiter;
- Identifier le goulot d’étranglement : Nous devons ensuite identifier le goulot d’étranglement de notre application c’est-à-dire la ou les taches demandant le plus de ressources CPU et qui bloque la boucle d’événements dans le cas de Node.js;
- Résoudre le problème de performance : Une fois le goulot d’étranglement identité, il faut résoudre celui-ci quand cela est possible;
- Vérifier la solution : Pour terminer, on vérifie la solution à l’aide d’un test de performance (Benchmark) et l’on s’assure que les performances répondent à notre objectif initial. Si ce n’est pas le cas, on recommence le processus jusqu’à satisfaction.
Pour la suite, nous allons prendre pour exemple la route d’une API REST sous Express permettant à un utilisateur de se connecter. Nous allons donc utiliser les JSON Web Tokens comme vu dans un précédent article.
Commençons tout d’abord par installer Express :
npm install --save expressPuis créons notre application :
const express = require('express')
const app = express()
app.listen(3000, () => console.log('App listening at http://localhost:3000'))Ajoutons ensuite une fonction permettant de vérifier le mot de passe fournit par l’utilisateur :
/** * Vérifie que le mot de passe correspond au hash fournit * @function checkPassword * @param {string} password - Le mot de passe à comparer * @param {saltAndHash} saltAndHash - La chaine de caractère contenant le sel et le hash * avec lequel le mot de passe doit être comparé * @returns {boolean} true si le mot de passe correspond au hash, false dans le cas contraire */function checkPassword (password, saltAndHash) { /* On convertit la saltAndHash en buffer */ const bytes = Buffer.from(saltAndHash, 'base64')
/* On extrait le sel et le hash */ const salt = bytes.slice(0, 128) const hash = bytes.slice(128)
/* On calcul le hash du mot de passe fournit avec le sel extrait */ const rehash = crypto.pbkdf2Sync(password, salt, 10000, 512, 'sha512')
/* On compare les deux hash */ return crypto.timingSafeEqual(hash, rehash)}Installons ensuite la librairie jsonwebtoken permettant de créer le JWT :
npm install --save jsonwebtokenPuis ajoutons la route permettant à un utilisateur de se connecter :
const jwt = require('jsonwebtoken')const { userService, refreshTokenService } = ('./db/services')const config = require('./config')
app.post('/login', express.json(), async (req, res) => { try { const { email, password } = req.body
/* On vérifie que l'email de l'utilisateur est présent dans la requête */ if (!email) { return res.status(400).json({ error: 'missing_required_parameters', context: { body: ['email'] } }) }
/* On vérifie que le mot de passe est présent dans la requête */ if (!password) { return res.status(400).json({ error: 'missing_required_parameters', context: { body: ['password'] } }) }
/* On récupère l'utilisateur via son email */ const user = await userService.findOne({ email })
/* On vérifie que l'utilisateur existe */ if (!user) { return res.status(401).json({ error: 'bad_credentials', message: 'Username or password is incorrect' }) }
/* On vérifie la correspondance des mots de passe */ if (!checkPassword(password, user.password)) { return res.status(401).json({ error: 'bad_credentials', message: 'Username or password is incorrect' }) }
/* On créer le token CSRF */ const xsrfToken = crypto.randomBytes(64).toString('hex')
/* On créer le JWT avec le token CSRF dans le payload */ const accessToken = jwt.sign( { firstName: user.firstName, lastName: user.lastName, xsrfToken }, config.accessToken.secret, { algorithm: config.accessToken.algorithm, audience: config.accessToken.audience, expiresIn: config.accessToken.expiresIn / 1000, // Le délai avant expiration exprimé en secondes issuer: config.accessToken.issuer, subject: user.id.toString() } )
/* On créer le refresh token et on le stocke en BDD */ const refreshToken = crypto.randomBytes(128).toString('base64')
await refreshTokenService.create({ userId: user.id, token: refreshToken, expiresAt: Date.now() + config.refreshToken.expiresIn })
/* On créer le cookie contenant le JWT */ res.cookie('access_token', accessToken, { httpOnly: true, secure: true, maxAge: config.accessToken.expiresIn // Le délai avant expiration exprimé en millisecondes })
/* On créer le cookie contenant le refresh token */ res.cookie('refresh_token', refreshToken, { httpOnly: true, secure: true, maxAge: config.refreshToken.expiresIn, path: '/token' })
/* On envoie une reponse JSON contenant les durées de vie des tokens et le token CSRF */ res.json({ accessTokenExpiresIn: config.accessToken.expiresIn, refreshTokenExpiresIn: config.refreshToken.expiresIn, xsrfToken })
} catch (err) { return res.status(500).json({ message: 'Internal server error' }) }})Rien de bien compliqué, nous avons vu plus ou moins le même code sur l’article concernant la gestion du JWT coté client. Voyons maintenant comment tester les performances de notre route.
Établir une base
La première étape du processus d’optimisation est d’établir les performances actuelles d’une application. Dans le cas de notre API REST, nous souhaitons déterminer le nombre de requêtes que notre route d’authentification est capable de satisfaire à la seconde. Nous allons pour cela utiliser des outils de benchmarking.
Benchmarking
Nous avons besoin dans notre cas d’un outil de benchmarking permettant de simuler des requêtes HTTP. Il en existe plusieurs sur le marché dont voici une liste non exhaustive :
- locust;
- gatling;
- ab;
- artillery;
- autocannon.
Tous ses outils sont géniaux, mais nous allons, pour cet article, nous intéresser à [autocannon](https://github.com/mcollina/autocannon) qui est très simple d’utilisation. Commençons donc par l’installer :
npm install autocannon -gComme je l’ai dit, son utilisation est très simple, il suffit de lancer la commande suivante :
autocannon [options] URLLes options qui nous intéresse sont les suivantes :
-c/--connections NUM Le nombre de connexions concurrentes. Par défaut: 10.-d/--duration SEC Le temps d'exécution d'autocannon en seconde. Par défaut: 10.-m/--method METHOD La méthode HTTP à utiliser. Par défaut: 'GET'.-b/--body BODY Le corps de la requête.-i/--input FILE Le chemin d'un fichier contenant le corps de la requête.Je vous invite à lire la documentation pour voir les autres options.
Testons donc notre API REST, pour cela lançons notre application :
NODE_ENV=production node server.jsPuis lançons la commande [autocannon](https://github.com/mcollina/autocannon) suivante :
autocannon -c 100 -m POST -b '{"email":"john@doe.com","password":"P@ssw0rd"}' -H Content-Type=application/json localhost:3000/loginSi vous êtes sous Windows, il est possible que cette commande ne fonctionne pas correctement. Dans ce cas il suffit d’échapper le caractère ” dans le paramètre body (-b) comme suit ”.
Cette commande lance 100 connexions simultanées pendant 10 secondes qui vont effectuer chacune d’entre elles, plusieurs requêtes POST (dès qu’une requête est terminée une autre est effectuée) avec comme paramètres de celles-ci l’email de l’utilisateur et son mot de passe.
Une fois la commande terminée, nous obtenons le résultat suivant :

229 requêtes ont étaient effectuées en 10 secondes avec une latence moyenne de 470 ms, ce qui fait environs 20 requêtes à la seconde.
Tentons donc de voir si quelque chose ne va pas dans notre code.
Identifier le goulot d’étranglement
La seconde étape du processus d’optimisation consiste à identifier le goulot d’étranglement de notre programme. Nous allons voir plusieurs outils nous permettant d’identifier celui-ci.
Profiler V8
Le premier outil que nous allons utiliser est le profiler du moteur javascript V8 qui est intégré avec Node.js. Le profiler permet de collecter à intervalle régulier (tick), les fonctions de notre application qui sont en cours d’exécution sur le CPU. Cet intervalle est par défaut de 1 ms.
Pour cela rien de plus simple, il suffit de lancer notre application avec l’option --prof permettant de collecter les ticks dans un fichier isolate-0xnnnnnnnnnnnn-v8.log :
NODE_ENV=production node --prof server.jsNous avons maintenant un fichier isolate-0xnnnnnnnnnnnn-v8.log contenant les ticks CPU :
tick,0x16a42ea,5803889,1,0xb439b0,6,0xbf1fe0,0x1436e6e96563,0x1436e6e95f22,0x1436e6e95372,0x137f1d3,0xa9b6c0,0x3948f2bff0d8tick,0x16a42c6,5804901,1,0xb439b0,6,0xbf1fe0,0x1436e6e96563,0x1436e6e95f22,0x1436e6e95372,0x137f1d3,0xa9b6c0,0x3948f2bff0d8tick,0x157eea9,5805964,1,0xb439b0,6,0xbf1fe0,0x1436e6e96563,0x1436e6e95f22,0x1436e6e95372,0x137f1d3,0xa9b6c0,0x3948f2bff0d8tick,0x16a4af0,5807063,1,0xb439b0,6,0xbf1fe0,0x1436e6e96563,0x1436e6e95f22,0x1436e6e95372,0x137f1d3,0xa9b6c0,0x3948f2bff0d8tick,0x16a40f1,5808125,1,0xb439b0,6,0xbf1fe0,0x1436e6e96563,0x1436e6e95f22,0x1436e6e95372,0x137f1d3,0xa9b6c0,0x3948f2bff0d8tick,0x16a465b,5809186,1,0xb439b0,6,0xbf1fe0,0x1436e6e96563,0x1436e6e95f22,0x1436e6e95372,0x137f1d3,0xa9b6c0,0x3948f2bff0d8tick,0x15ee9a9,5810247,1,0xb439b0,6,0xbf1fe0,0x1436e6e96563,0x1436e6e95f22,0x1436e6e95372,0x137f1d3,0xa9b6c0,0x3948f2bff0d8...Celui-ci est par contre difficile à analyser pour un être humain. Heureusement, il existe une commande Node.js permettant de rendre ce fichier compréhensible. Il suffit pour cela de lancer Node.js avec la commande --prof-process :
node --prof-process isolate-0xnnnnnnnnnnnn-v8.logRemplacer bien entendu isolate-0xnnnnnnnnnnnn-v8.log par le nom du fichier généré précédemment. Après quelques secondes, un rapport concernant la répartition des “ticks” collectés est généré. Ce rapport est découpé en six sections.
Shared libraries
[Shared libraries]: ticks total nonlib name 238 2.3% /home/arkerone/.nvm/versions/node/v12.18.4/bin/node 16 0.2% [vdso] 10 0.1% /usr/lib/x86_64-linux-gnu/libc-2.31.so 1 0.0% /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.28Cette section permet de connaitre la consommation de temps CPU des bibliothèques ou programmes liés au système d’exploitation.
JavaScript
[JavaScript]: ticks total nonlib name 1 0.0% 0.0% RegExp: ^[\u0009\u0020-\u007e\u0080-\u00ff]+$ 1 0.0% 0.0% RegExp: [^\t\x20-\x7e\x80-\xff] 1 0.0% 0.0% LazyCompile: *normalizeString path.js:52:25 1 0.0% 0.0% LazyCompile: *next /media/arkerone/DATA/developpement/labs/cpu-profiling/node_modules/express/lib/router/index.js:176:16Cette section permet de connaitre la consommation de temps CPU du code JavaScript. Celui de notre code source, mais également des modules tiers.
C++
[C++]: ticks total nonlib name 22122 96.5% 98.3% node::crypto::PBKDF2(v8::FunctionCallbackInfo<v8::Value> const&) 74 0.3% 0.3% __write 54 0.2% 0.2% node::native_module::NativeModuleEnv::CompileFunction(v8::FunctionCallbackInfo<v8::Value> const&) 42 0.2% 0.2% node::fs::InternalModuleStat(v8::FunctionCallbackInfo<v8::Value> const&) 41 0.2% 0.2% void node::StreamBase::JSMethod<&node::StreamBase::Writev>(v8::FunctionCallbackInfo<v8::Value> const&) 37 0.2% 0.2% node::contextify::ContextifyContext::CompileFunction(v8::FunctionCallbackInfo<v8::Value> const&) 23 0.1% 0.1% node::fs::InternalModuleReadJSON(v8::FunctionCallbackInfo<v8::Value> const&) 20 0.1% 0.1% node::fs::LStat(v8::FunctionCallbackInfo<v8::Value> const&) 11 0.0% 0.0% node::fs::Open(v8::FunctionCallbackInfo<v8::Value> const&)...Node.js étant construit sur le moteur V8, certaines API de la bibliothèque standard de Node.js sont écrites en C++. D’autres modules externes peuvent également être écrits en C++, cette section permet donc de connaitre la consommation de temps CPU de la bibliothèque standard de Node.js et de ses modules externes.
On remarque pour notre cas que la fonction node::crypto::PBKDF2(v8::FunctionCallbackInfo<v8::Value> const&) consomme 96.5% du temps total d’exécution, il s’agit donc de notre goulot d’étranglement.
C++ entry points
[C++ entry points]: ticks cpp total name 22391 99.2% 97.7% v8::internal::Builtin_HandleApiCall(int, unsigned long*, v8::internal::Isolate*) 109 0.5% 0.5% node::task_queue::RunMicrotasks(v8::FunctionCallbackInfo<v8::Value> const&) 28 0.1% 0.1% __write 13 0.1% 0.1% v8::internal::Builtin_JsonParse(int, unsigned long*, v8::internal::Isolate*) 4 0.0% 0.0% v8::internal::Builtin_DatePrototypeToUTCString(int, unsigned long*, v8::internal::Isolate*) 3 0.0% 0.0% v8::internal::Builtin_JsonStringify(int, unsigned long*, v8::internal::Isolate*) 2 0.0% 0.0% v8::internal::Builtin_FunctionPrototypeToString(int, unsigned long*, v8::internal::Isolate*) 2 0.0% 0.0% v8::internal::Builtin_ArrayBufferConstructor(int, unsigned long*, v8::internal::Isolate*)...Cette section, permet de connaitre la consommation de temps CPU passé dans les fonctions d’entrées C++ c’est-à-dire les fonctions qui ont été appelées lorsque le code est passé de JavaScript à C++.
Summary
[Summary]: ticks total nonlib name 4 0.0% 0.0% JavaScript 22503 98.2% 100.0% C++ 12 0.1% 0.1% GC 410 1.8% Shared libraries 1 0.0% UnaccountedCette section permet d’avoir un résumé concernant la répartition des ticks permettant de voir rapidement quelle partie prend le plus de temps CPU. Ce résumé concerne cinq parties à savoir le code JavaScript, le code C++, le garbage collector (GC), les librairies ou programmes liés au système d’exploitation (Shared libraries) ou les ticks non comptabilisés (unaccounted).
On remarque que 98.2% du temps CPU est passé dans la partie C++. C’est justement ce que l’on avait vu plus haut.
Bottom up (heavy) profile :
[Bottom up (heavy) profile]: Note: percentage shows a share of a particular caller in the total amount of its parent calls. Callers occupying less than 1.0% are not shown.
ticks parent name 22122 96.5% node::crypto::PBKDF2(v8::FunctionCallbackInfo<v8::Value> const&) 22122 100.0% v8::internal::Builtin_HandleApiCall(int, unsigned long*, v8::internal::Isolate*) 22122 100.0% LazyCompile: ~pbkdf2Sync internal/crypto/pbkdf2.js:45:20 22122 100.0% LazyCompile: ~checkPassword /media/arkerone/DATA/developpement/labs/cpu-profiling/src/server.js:45:24 22122 100.0% LazyCompile: ~<anonymous> /media/arkerone/DATA/developpement/labs/cpu-profiling/src/server.js:62:36 22122 100.0% /home/arkerone/.nvm/versions/node/v12.18.4/bin/node...Cette partie est la plus intéressante, elle permet de voir la pile d’appels des fonctions (call stack) consommant le plus de temps CPU. Sans surprise, on retrouve la fonction C++ node::crypto::PBKDF2(v8::FunctionCallbackInfo<v8::Value> const&).
On voit également qui a appelé cette fonction et l’on remarque que c’est notre fonction checkPassword qui pose problème.
Bonus : On remarque que le nom des fonctions JavaScript sont précédaient de LazyCompile qui est un nom d’événement du moteur V8 signifiant que la fonction est compilée et optimisée à la demande. On retrouve également d’autres noms d’événements tels que RegExp, Eval ou encore Function.
Le nom de la fonction est également préfixé par le caractère ~ . Cela signifie que le temps CPU consommé s’est fait dans une fonction non optimisée par le moteur V8. On trouve le caractère * dans le cas d’une fonction optimisée. Bon, vous ne devez surement pas comprendre grand-chose, mais ce n’est pas grave, on rentre dans le fonctionnement interne du moteur V8 ce qui sort totalement du cadre de cet article, je parlerais de V8 surement un jour dans un autre article, bref continuons.
Chrome devTools
Un autre moyen de profiler notre application est d’utiliser Chrome devTools. Pour se faire lançons notre application avec l’option --inspect:
NODE_ENV=production node --inspect server.jsOuvrons ensuite chrome et renseignons dans la barre d’adresse chrome://inspect ce qui ouvre la page suivante :
Cliquons ensuite sur le lien (inspect) de notre application, la fenêtre suivante s’ouvre :
Pour démarrer le profiling CPU, cliquons sur le bouton Start et lançons la commande autocannon suivante :
autocannon -c 100 -m POST -b '{"email":"john@doe.com","password":"P@ssw0rd"}' -H Content-Type=application/json localhost:3000/loginUne fois la commande autocannon terminée, arrêtons le profiling CPU en cliquant le bouton Stop.
On peut maintenant analyser la consommation de temps CPU de notre application. Pour cela, nous disposons de trois vues différentes :
- Heavy (Bottom Up) : Cette vue permet de voir quelles fonctions ont eu le plus d’impact sur les performances et d’examiner la pile d’appels (call stack);
- Chart : Cette vue fournit une représentation visuelle de ce qui est en cours d’exécution sur le CPU au fil du temps;
- Tree (Top Down) : Cette vue permet de voir l’arborescence des appels de fonctions avec les points d’entrée d’exécution affichés en haut, c’est l’inverse de la vue Heavy (Bottom Up);
Nous allons nous intéresser uniquement aux deux premières vues.
Heavy (Bottom Up)
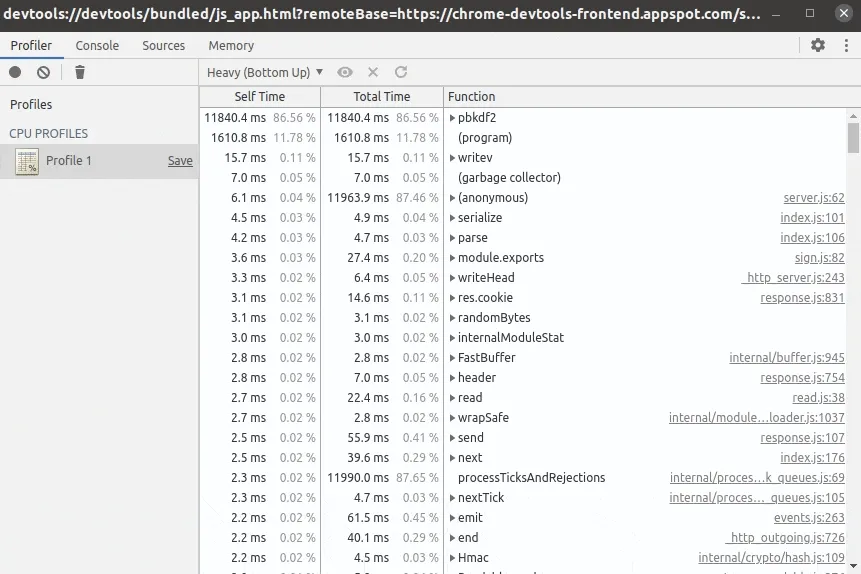
Cette vue est découpée en trois parties :
- Self time : Le temps cumulé passé dans la fonction elle-même sans prendre en compte le temps passé dans les fonctions appelées par celle-ci;
- Total time : Le temps total cumulé passé dans la fonction y compris les fonctions appelées par celle-ci;
- Function : Le nom de la fonction suivi de l’emplacement de celle-ci dans le code source.
Dans notre exemple, on remarque que c’est la fonction pbkdf2Sync qui se trouve dans notre fonction checkPassword qui pose problème.
Chart
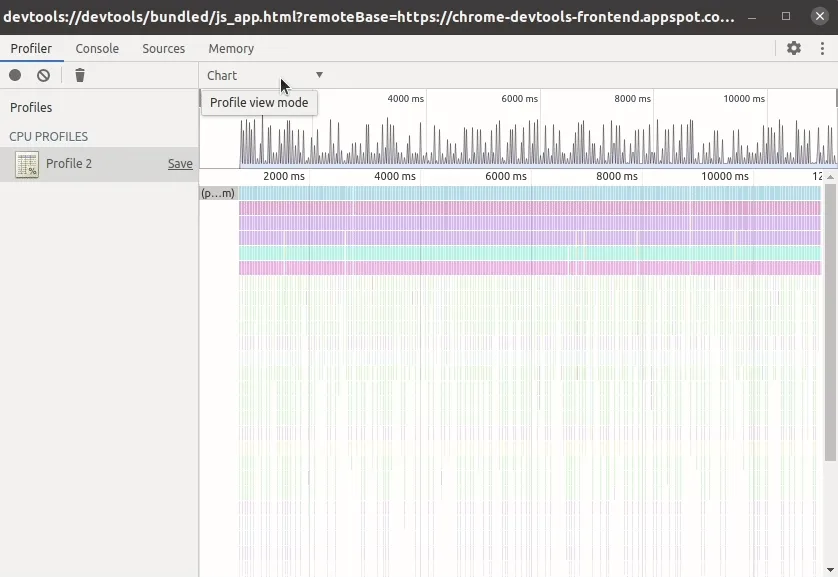
Cette vue permet d’avoir une représentation visuelle de ce qui est en cours d’exécution sur le CPU à un instant t. Nous avons sur l’axe des abscisses la chronologie d’exécution du profiling et sur l’axe des ordonnées la pile d’appels des fonctions (call stack).
Chaque bloc de couleur représente un appel de fonction (les couleurs sont aléatoires et n’ont aucune signification particulière). Lors d’un passage de la souris sur l’un de ces blocs, nous avons les informations suivantes :
- Name : Le nom de la fonction;
- Self time : Le temps passé dans la fonction elle-même sans prendre en compte le temps passé dans les fonctions appelées par celle-ci;
- Total time : Le temps total passé dans la fonction y compris les fonctions appelées par celle-ci;
- Aggregated self time : Le temps cumulé passé dans la fonction elle-même sans prendre en compte le temps passé dans les fonctions appelées par celle-ci;
- Aggregated total time : Le temps total cumulé passé dans la fonction y compris les fonctions appelées par celle-ci
Attention, l’axe des ordonnées représente la pile d’appels, c’est la fonction qui se trouve en haut de cette pile d’appels qui est en cours d’exécution sur le CPU c’est pourquoi les informations “Self time” et “Total time” sont intéressantes.
Plus un bloc est large, plus la fonction associée consomme du temps CPU. Dans le cas de notre exemple, on remarque bien que c’est la fonction pbkdf2Sync qui se trouve dans notre fonction checkPassword qui pose problème.
Notre exemple est relativement simple, mais dans certains cas beaucoup plus complexes, cette représentation sous forme de graphique pose un souci. En effet, il est compliqué de voir d’un simple coup d’oeil quelle fonction prend le plus de temps CPU pour toute la durée du profiling.
Flamegraph
La représentation graphique de Chrome Devtools est fort pratique, mais nous aurions besoin d’un outil permettant de visualiser les fonctions qui consomment le plus de temps CPU sur l’ensemble de la durée du profiling. Pour faire simple, il nous faut un outil qui est une représentation visuelle du profiler V8 intégré à Node.js. Et c’est là qu’entrent en jeu les flamegraphs.
Pour comprendre ce qu’est un flamegraph, voici un petit schéma :
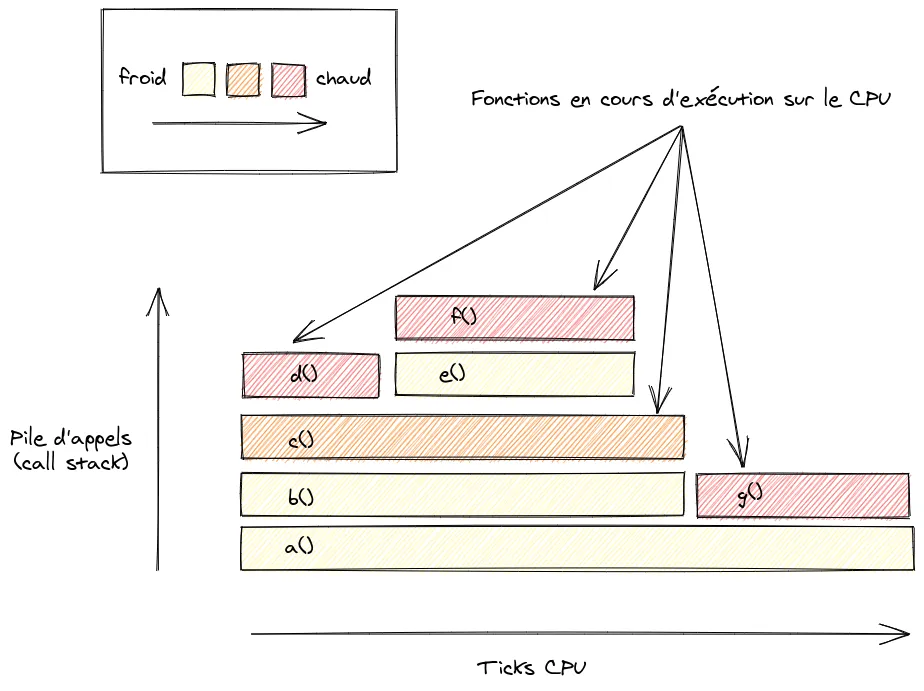
- L’axe des abscisses : Attention, il ne représente pas la chronologie d’exécution, mais plutôt les ticks CPU. Chaque bloc représente une fonction, plus le bloc est large et plus la fonction consomme du temps CPU. Généralement, les fonctions sont triées par ordre alphabétique ou suivant la largeur du bloc en bas de la pile d’appels. Suivant l’outil utilisé, la couleur du bloc peut avoir une signification. Par exemple, plus une fonction est jaune c’est-à-dire “froide”, moins elle a passé de temps sur le CPU. Au contraire, plus elle se rapproche du rouge, plus celle-ci est “chaude” et donc, plus elle a passé de temps sur le CPU;
- L’axe des ordonnées : Représente la pile d’appels de fonctions (call stack). C’est la fonction qui se trouve en haut de cette pile d’appels qui est réellement en cours d’exécution sur le CPU, celle qui se trouve en dessous est la fonction appelante;
Il existe plusieurs outils permettant de générer un flamegraph, dont voici une liste non exhaustive :
Nous allons nous intéresser à ce dernier, installons donc celui-ci :
npm install -g clinicClinicJs, fournit trois outils en un. Celui qui nous intéresse est flame. Pour l’utiliser il suffit de lancer la commande suivante :
clinic flame [options] -- node server.jsLes options qui nous intéressent sont les suivantes :
--autocannon Permets de lancer autocannon en lui passant ses options entre [ ].--on-port Permets de lancer une commande une fois que l'application est en écoute sur un port.Je vous invite à lire la documentation pour voir les autres options.
Générons donc un flamegraph pour notre route d’authentification :
NODE_ENV=production clinic flame --autocannon [/login -c 100 -m POST -b '{"email":"john@doe.com","password":"P@ssw0rd"}' --headers Content-Type=application/json] -- node server.jsUne fois l’exécution terminée, une page web s’ouvre avec notre flamegraph.
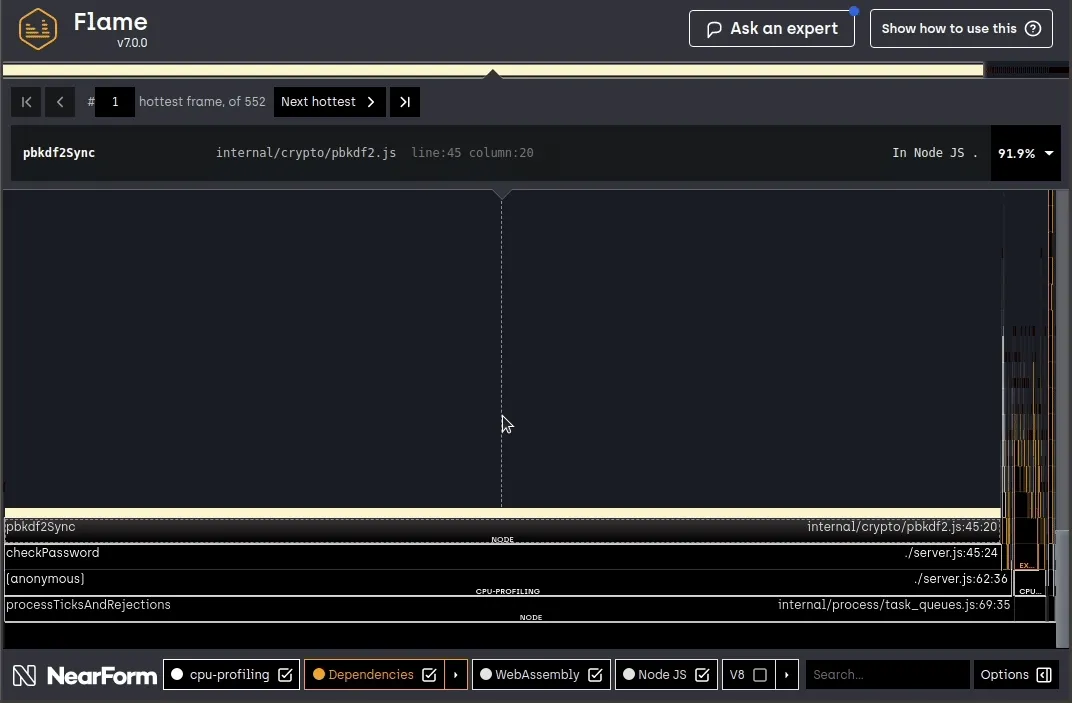
Comme je l’ai dit précédemment, des couleurs peuvent être associées au temps passé sur le CPU. Dans le cas de Clinic flame, les couleurs sont associées aux fonctions uniquement en cours d’exécution sur le CPU, plus un bloc est clair plus il a passé du temps sur le CPU et plus il est foncé moins il a passé du temps sur le CPU.
On remarque immédiatement que la fonction pbkdf2Sync appelée par notre fonction checkPassword occupe la majorité du temps CPU (c’est le bloc le plus large et le plus clair au-dessus de la pile d’appels).
Clinic flame propose également des options permettant d’afficher les appels aux fonctions C++ comme on peut le voir dans l’image ci-dessus.
Pour ceux que ça intéresse, vous pouvez retrouver ce flamegraph ici.
Résoudre le problème
Nous avons trouvé notre goulot d’étranglement, il s’agit de la fonction pbkdf2Sync appelée par notre fonction checkPassword qui bloque l’event loop. En parcourant la documentation de Node.js nous remarquons qu’il existe une version asynchrone à la fonction pbkdf2Sync. Modifions notre code pour utiliser celle-ci à la place :
const { promisify } = require('util')
/* On transforme la fonction pbkdf2 pour qu'elle nous retourne une promesse */const pbkdf2Async = promisify(crypto.pbkdf2)
/** * Vérifie que le mot de passe correspond au hash fournit * @async * @function checkPassword * @param {string} password - Le mot de passe à comparer * @param {saltAndHash} saltAndHash - La chaine de caractère contenant le sel et le hash * avec lequel le mot de passe doit être comparé * @returns {Promise<boolean>} true si le mot de passe correspond au hash, false dans le cas contraire */async function checkPassword (password, saltAndHash) { /* On convertit la saltAndHash en buffer */ const bytes = Buffer.from(saltAndHash, 'base64')
/* On extrait le sel et le hash */ const salt = bytes.slice(0, 128) const hash = bytes.slice(128)
/* On calcul le hash du mot de passe fournit avec le sel extrait */ const rehash = await pbkdf2Async(password, salt, 10000, 512, 'sha512')
/* On compare les deux hash */ return crypto.timingSafeEqual(hash, rehash)}Modifions ensuite le code de notre login “login”:
/* On vérifie la correspondance des mots de passe */if (!await checkPassword(password, user.password)) { return res.status(401).json({ error: 'bad_credentials', message: 'Username or password is incorrect' })}Relançons ensuite notre commande Clinic flame :
NODE_ENV=production clinic flame --autocannon [/login -c 100 -m POST -b '{"email":"john@doe.com","password":"P@ssw0rd"}' --headers Content-Type=application/json] -- node server.jsNous obtenons le résultat autocannon suivant :

Nous sommes passés de 20 requêtes en moyenne à la seconde à 66 requêtes et de 470 ms de latence moyenne à 147 ms. Nous avons donc multiplié par 3 le nombre de requêtes à la seconde et divisé par 3 la latence. Ce n’est pas mal, sachant que la fonction pbkdf2 est volontairement lente pour éviter le cassage du mot de passe par brute force.
Voici le flamegraph correspond que vous pouvez également retrouver ici :
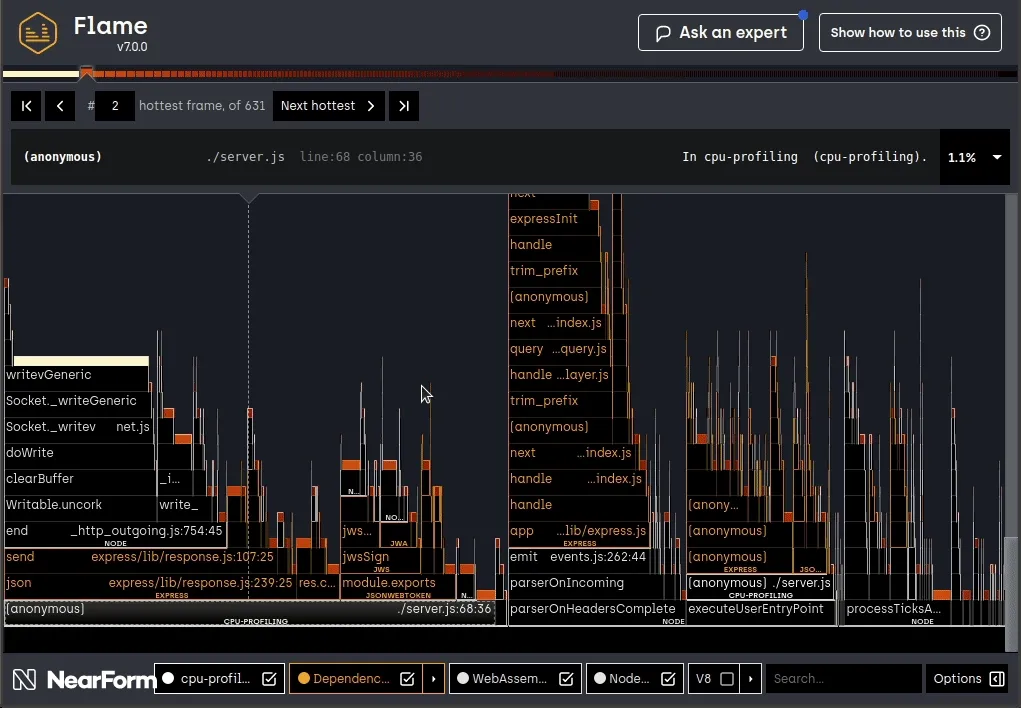
C’est tout de même beaucoup mieux ! Il reste la fonction writevGeneric, mais sans rentrer dans les détails de ce qui se passe en interne, nous ne pouvons pas optimiser celle-ci. Par contre, même si le gain sera minime nous pouvons optimiser les fonctions randomBytes et jwt.sign qui ont tous les deux également une version asynchrone.
Notre code final optimisé est donc le suivant :
const jwt = require('jsonwebtoken')const { userService, refreshTokenService } = ('./db/services')const config = require('./config')
const { promisify } = require('util')
const pbkdf2Async = promisify(crypto.pbkdf2)const randomBytesAsync = promisify(crypto.randomBytes)const jwtSignAsync = promisify(jwt.sign)
app.post('/login', express.json(), async (req, res) => { try { const { email, password } = req.body
/* On vérifie que l'email de l'utilisateur est présent dans la requête */ if (!email) { return res.status(400).json({ error: 'missing_required_parameters', context: { body: ['email'] } }) }
/* On vérifie que le mot de passe est présent dans la requête */ if (!password) { return res.status(400).json({ error: 'missing_required_parameters', context: { body: ['password'] } }) }
/* On récupère l'utilisateur via son email */ const user = await userService.findOne({ email })
/* On vérifie que l'utilisateur existe */ if (!user) { return res.status(401).json({ error: 'bad_credentials', message: 'Username or password is incorrect' }) }
/* On vérifie la correspondance des mots de passe */ if (!await checkPassword(password, user.password)) { return res.status(401).json({ error: 'bad_credentials', message: 'Username or password is incorrect' }) }
/* On créer le token CSRF */ const xsrfToken = (await randomBytesAsync(64)).toString('hex')
/* On créer le JWT avec le token CSRF dans le payload */ const accessToken = await jwtSignAsync( { firstName: user.firstName, lastName: user.lastName, xsrfToken }, config.accessToken.secret, { algorithm: config.accessToken.algorithm, audience: config.accessToken.audience, expiresIn: config.accessToken.expiresIn / 1000, // Le délai avant expiration exprimé en secondes issuer: config.accessToken.issuer, subject: user.id.toString() } )
/* On créer le refresh token et on le stocke en BDD */ const refreshToken = (await randomBytesAsync(128)).toString('base64')
await refreshTokenService.create({ userId: user.id, token: refreshToken, expiresAt: Date.now() + config.refreshToken.expiresIn })
/* On créer le cookie contenant le JWT */ res.cookie('access_token', accessToken, { httpOnly: true, secure: true, maxAge: config.accessToken.expiresIn // Le délai avant expiration exprimé en millisecondes })
/* On créer le cookie contenant le refresh token */ res.cookie('refresh_token', refreshToken, { httpOnly: true, secure: true, maxAge: config.refreshToken.expiresIn, path: '/token' })
/* On envoie une reponse JSON contenant les durées de vie des tokens et le token CSRF */ res.end()
} catch (err) { console.log(err) return res.status(500).json({ message: 'Internal server error' }) }})Relançons notre application :
NODE_ENV=production node server.jsPuis la commande autocannon suivante pour vérifier si nous avons amélioré les résultats :
autocannon -c 100 -m POST -b '{"email":"john@doe.com","password":"P@ssw0rd"}' -H Content-Type=application/json localhost:3000/loginOn obtient donc le résultat suivant :
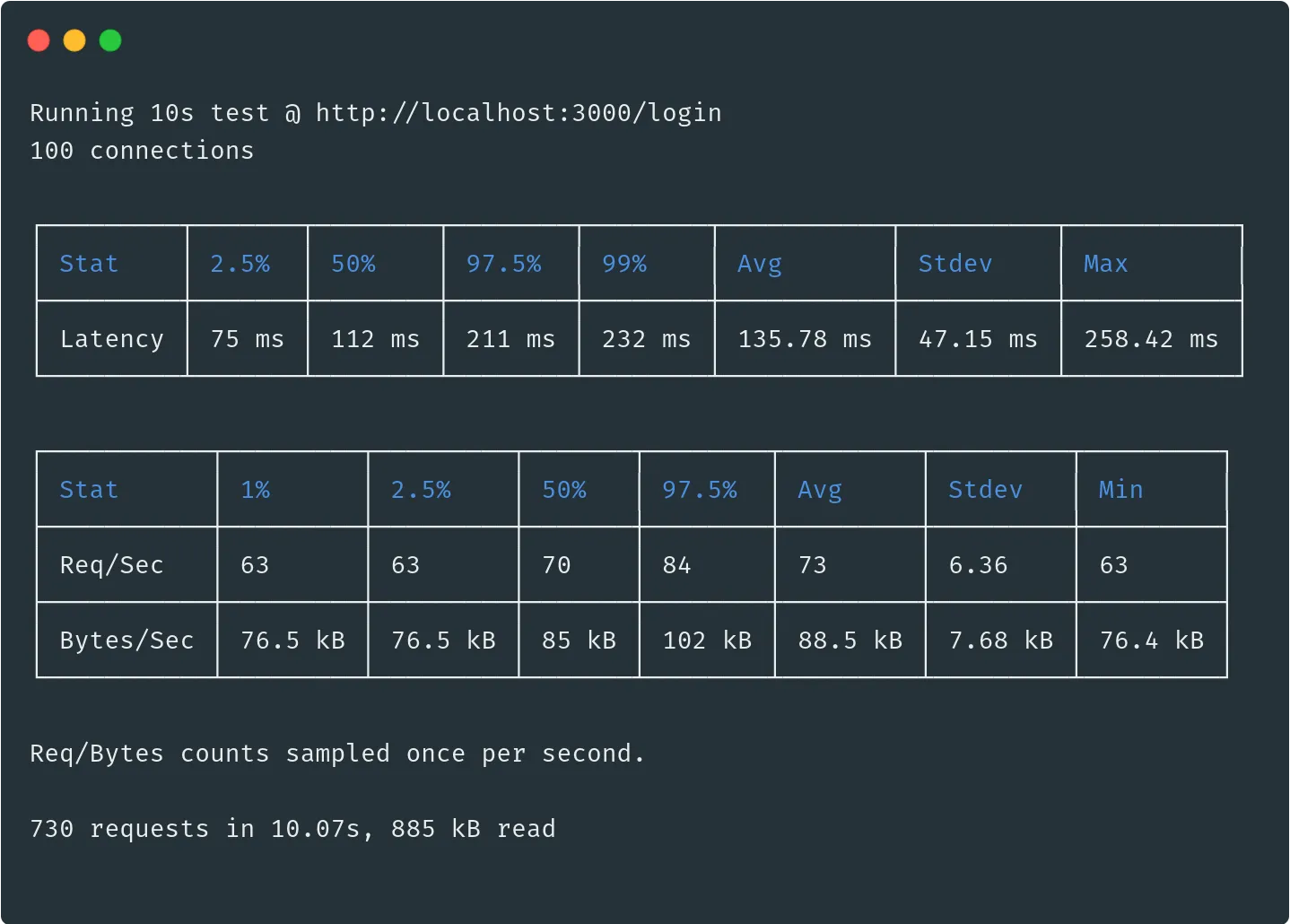
Nous avons réussi à gagner quelques requêtes par seconde et réduire légèrement la latence.
Quelques conseils
Avant de terminer, nous allons voir quelques conseils assez simples lorsque l’on écrit du code Node.js pour éviter de bloquer l’event loop et donc réduire les performances.
Utiliser les versions asynchrones des fonctions
Comme nous l’avons vu dans l’exemple de cet article, il faut toujours privilégier les versions asynchrones des fonctions, car celles-ci ne bloquent pas l’event loop contrairement à leurs versions synchrones.
Le seul moment où vous pouvez utiliser la version synchrone d’une fonction est lors du démarrage et l’initialisation de votre application.
Augmenter la taille du thread pool
Pour implémenter le design pattern “Reactor” vu en début d’article, Node.js utilise la librairie libuv. Pour certains traitements asynchrones, celle-ci utilise un pool de thread dont il est possible d’augmenter la taille jusqu’à 128 via la variable d’environnement UV_THREADPOOL_SIZE . Les fonctions qui utilisent le pool de thread sont les suivantes :
- Toutes les fonctions du module
fsqui sont asynchrone exceptéfs.FSWatcher; - Les fonctions
crypto.pbkdf2(),crypto.scrypt(),crypto.randomBytes(),crypto.randomFill(),crypto.generateKeyPair()du modulecrypto; - Toutes les fonctions du module
zlibqui sont asynchrone; - Les fonctions
dns.lookup(),dns.lookupService()du moduledns.
Dans l’exemple de cet article, nous utilisons justement crypto.pbkdf2() et crypto.randomBytes() je vous laisse donc tester en augmentant la taille du pool de thread et voir le résultat.
Utiliser les workers threads pour les traitements lourds
Si vous souhaitez réaliser une opération CPU intense de façon synchrone, il est recommandé d’utiliser les workers threads je vous invite à aller lire ce très bon article sur le sujet.
Pour finir
On vient de voir un exemple assez simple afin de comprendre comment utiliser les outils permettant d’analyser les performances CPU de notre application et comment améliorer celles-ci.
Le sujet est très vaste et celui-ci peut vite devenir extrêmement technique. J’ai tout de même tenté de synthétiser au maximum les informations afin de vous mettre le pied à l’étrier. Libre à vous par la suite de pousser le sujet un peu plus loin en vous documentant sur l’utilisation des outils et des techniques d’optimisation. Je ferais peut-être un jour un article un peu plus avancé sur le sujet.
Cet article, bien que déjà assez dense, n’est que le premier d’une série de quatre articles, les suivants porteront sur l’analyse de la mémoire, des traitements asynchrones, et sur un profiler pensé pour les agents IA.
SI l’article vous a plu n’hésitez pas à me le dire en commentaire et de me suivre sur Twitter !



{kind=link}
{kind=link}
Partage ta réflexion, pose une question ou laisse un retour.