
Troisième article de cette série consacrée à l’analyse des performances des applications Node.js. Aujourd’hui nous allons voir comment analyser les traitements asynchrones.
Pour rappel, cette série se compose de quatre articles :
- Analyse des performances CPU ;
- Analyse de la mémoire ;
- Analyse des traitements asynchrones ;
- Un profiler pensé pour les agents IA.
Comme toujours, le code présenté dans mes articles est fonctionnel, mais simplifié pour se concentrer uniquement sur les concepts clés et appréhender l’utilisation des outils.
Comment analyser les traitements asynchrones ?
Vous devez maintenant comprendre assez bien comment fonctionne Node.js, si ce n’est pas le cas je vous invite à aller lire mon article sur l’event loop ou au moins la première partie de l’article sur l’analyse des traitements CPU avant de continuer.
On sait que Node.js repose principalement sur l’utilisation de traitements asynchrones mais contrairement à l’analyse des performances CPU ou de la mémoire, l’analyse de ces traitements asynchrones n’est pas chose aisée.
Une méthode naïve consisterait à mesurer le temps d’exécution d’une fonction asynchrone en utilisant le module perf_hooks comme ceci :
const { PerformanceObserver, performance } = require('perf_hooks')
/* On crée un nouvel objet PerformanceObserver permettant d'observer les événements de mesures de performances */const observer = new PerformanceObserver((data) => { const entries = data.getEntries() for (let { name, entryType: type, duration } of entries) { console.table({ name, type, duration }) }
performance.clearMarks()})
/* On indique que l'on souhaite observer les évenements de type "measure" */observer.observe({ entryTypes: ['measure'] })
/* On crée un premier point de mesure que l'on nomme "start_async" qui est le point de départ de lamesure */performance.mark('start_async')
/* On lance le traitement asynchrone */
await process()
/* On crée le second point de mesure que l'on nomme "end_async" */performance.mark('end_async')
/* On effectue ensuite la mesure que l'on nomme "Async measure" qui est ladifférence entre le premier point de mesure "start_async" et le second "end_async" */performance.measure('Async measure', 'start_async', 'end_async')L’instruction console.table affiche le résultat suivant :

Le premier souci avec cette approche est qu’elle est intrusive. En effet, nous devons créer des points de mesures (via la performance.mark) dans chaque partie de code que l’on souhaite analyser. Le second souci est que nous ne savons pas réellement quand a débuté le traitement asynchrone, celui-ci est peut-être en attente de la fin d’un autre traitement démarré plus tôt, la mesure peut donc être faussée.
Async_hooks à la rescousse
Au moment de l’écriture de cet article (décembre 2020), le module async_hooks est toujours à l’état expérimental.
Pour remédier aux problèmes cités précédemment, Node.js a introduit, dans sa version 8, le module async_hooks. Celui-ci propose une API permettant de suivre le cycle de vie des ressources asynchrones.
Une ressource asynchrone est un objet avec une fonction de callback associée, créée par Node.js. Ces ressources peuvent être de plusieurs types, par exemple les promesses (l’objet Promise), les timers (lors d’un appel à la fonction setTimeout, Node.js créé un objet Timeout), les appels aux fonctions du module fs, bref tout ce qui touche aux appels asynchrones.
Pour suivre le cycle de vie de ces ressources asynchrones, le module async_hooks fournit la fonction createHook. Cette fonction prend en paramètre un objet contenant les callbacks pour chacun des événements du cycle de vie. Ce qui nous donne le code suivant :
const async_hooks = require('async_hooks')
const asyncHook = async_hooks.createHook({ init: function (asyncId, type, triggerAsyncId, resource) {}, before: function (asyncId) {}, after: function (asyncId) {}, destroy: function (asyncId) {}, promiseResolve: function (asyncId) {}});
/* On active l'écoute sur chacun des événements du cycle de vie */asyncHook.enable()
/* La fonction "disable" permet d'arrêter l'écoute */asyncHook.disable()Voyons à quoi correspond chacune des fonctions de callback :
init: Appelée lors de la création de la ressource. Les paramètres sont les suivants :asyncId: Un identifiant unique de la ressource ;type: Une chaîne de caractères indiquant le type de la ressource par exempleTimeoutouPROMISE. La liste complète est disponible sur la documentation officielle ;triggerAsyncId: L’asyncIdde la ressource parente. Cet identifiant est très utile et permet de connaître la hiérarchie des appels asynchrone ;resource: L’objet qui correspond à la ressource créée.
before: Appelée avant l’appel de la fonction de callback de la ressource ;after: Appelée une fois l’appel à la fonction de callback de la ressource terminé ;destroy: Appelée lors de la destruction de la ressource;promiseResolve: Appelée quand la fonctionresolve()d’une promesse est appelée.
Voyons maintenant comment modifier le code vu précédemment pour mesurer les performances de nos appels asynchrones. Pour cela nous allons avoir besoin de créer un callback sur les événements init et after :
const async_hooks = require('async_hooks')const { performance, PerformanceObserver,} = require('perf_hooks')
/*On définit une liste de type de ressource à observer. la liste complète se trouve ici :https://nodejs.org/api/async_hooks.html#async_hooks_type **/const OBSERVED_TYPES = { Timeout: true, PROMISE: true,}
/* On créer une map pour stocker les informations de la ressource que l'on va observer */const resourcesMetaData = new Map()
const hook = async_hooks.createHook({ init (asyncId, type, triggerAsyncId, resource) { if (OBSERVED_TYPES[type]) { resourcesMetaData.set(asyncId, { type, triggerAsyncId, resource, })
performance.mark(`${type}-${asyncId}-before`) } }, after (asyncId) { if (resourcesMetaData.has(asyncId)) { const { type } = resourcesMetaData.get(asyncId) performance.mark(`${type}-${asyncId}-after`) performance.measure( `Measure ${type}-${asyncId}`, `${type}-${asyncId}-before`, `${type}-${asyncId}-after`, ) resourcesMetaData.delete(asyncId) performance.clearMarks(`${type}-${asyncId}-before`) performance.clearMarks(`${type}-${asyncId}-after`) } },})
hook.enable()
const observer = new PerformanceObserver((data) => { const entries = data.getEntries() for (let { name, entryType: type, duration } of entries) { console.table({ name, type, duration, }) }})
observer.observe({ entryTypes: ['measure'],})Exécutons maintenant dans un autre fichier le code suivant :
/* L'instruction setTimeout à observer */setTimeout(() => {}, 1000)L’instruction console.table affiche le résultat suivant :

Avec l’utilisation du module async_hooks nous n’avons pas besoin de modifier le code existant, contrairement à notre premier exemple. Nous avons également un vrai contrôle sur le cycle de vie des ressources asynchrones.
Je pourrais encore parler longuement de l’utilisation du module async_hooks et tout ce qu’il est possible de faire avec, mais ce n’est pas le but de cet article. On y reviendra sûrement dans un article dédié.
Tout ça, c’est bien beau, mais notre exemple est relativement simple, si l’on prend un exemple plus complexe avec plusieurs appels asynchrones on va vite s’y perdre.
Bien entendu on pourrait améliorer notre exemple et stocker le temps de chaque appel asynchrone pour nos ressources ainsi que la hiérarchie des appels et l’afficher de manière plus propre, mais ça demande beaucoup de travail et ce n’est pas aussi simple à analyser. Mais comment faire ?
Bubbleprof le magnifique
Depuis le début de cette série, je vous présente [ClinicJS](https://clinicjs.org/) avec notamment les outils Clinic flame et Clinic doctor. Pour ce troisième article, nous allons continuer sur cette lancée et voir le dernier outil de ClinicJS qui se nomme [Clinic bubbleprof](https://clinicjs.org/bubbleprof/). Bubbleprof utilise en interne le module async_hooks pour analyser les traitements asynchrones.
Si ce n’est pas déjà fait, installons ClinicJS via la commande suivante :
npm install -g clinicComme j’aime bien les exemples concrets, nous allons prendre un exemple qui s’inspire d’un projet sur lequel j’ai été amené à travailler.
Imaginons une application permettant de partager ses performances sportives avec ses amis, une sorte de réseau social dédié au sport. Sur cette application on souhaite afficher des statistiques (par exemple le nombre d’heures de sport effectuées, le nombre d’amis, le nombre de publications, etc.).
Pour récupérer ses informations, l’application doit effectuer des appels API à chacun des microservices concernés mais les développeurs front ne sont pas contents car cela multiplie les appels APIs et ils souhaiteraient effectuer qu’un seul appel pour récupérer l’ensemble des statistiques (bon dans la réalité le problème était beaucoup plus complexe que ça).
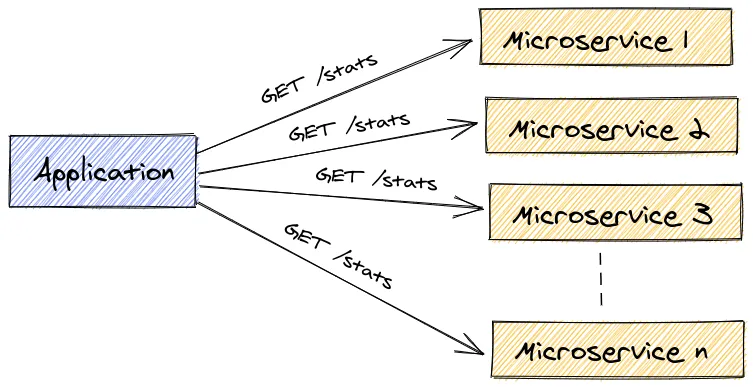
Pour faire plaisir à nos chers développeurs front, nous allons créer un microservice de statistiques permettant d’effectuer les différents appels APIs aux microservices concernés et renvoyer l’ensemble des statistiques via un seul appel API.
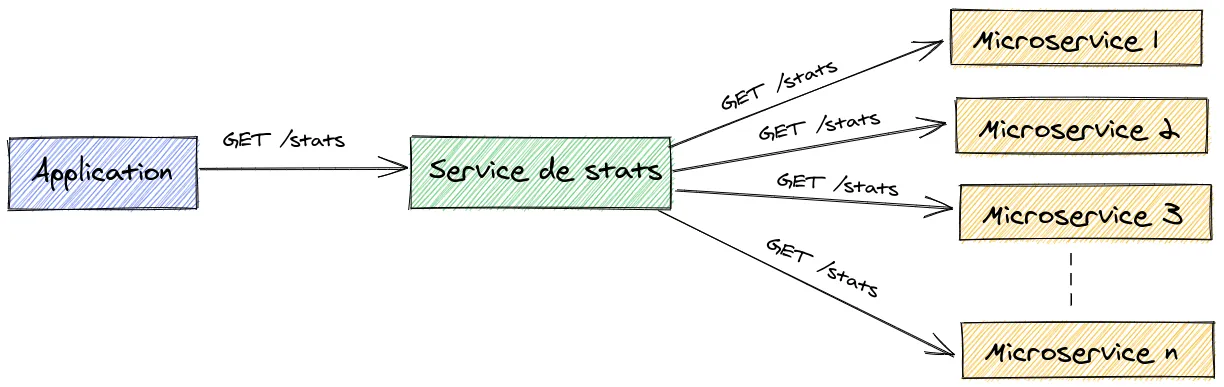
Le code de notre microservice de statistiques est le suivant :
const express = require('express')const { getActivitiesStats, getFriendsStats, getPostsStats, getHealthStats} = require('./services')
const app = express()
app.get('/stats', async (req, res, next) => { const activitiesStats = await getActivitiesStats() const friendsStats = await getFriendsStats() const healthStats = await getPostsStats() const postsStats = await getHealthStats()
res.json({ activities: activitiesStats, friends: friendsStats, health: healthStats, posts: postsStats })})
app.listen(3000, () => console.log('App listening at http://localhost:3000'))Le code est très simple, on effectue des appels APIs via les fonctions getActivitiesStats, getFriendsStats, getPostsStats et getHealthStats sur les différents microservices et on retourne le résultat de chacun de ses appels dans une réponse JSON.
Nous allons donc tester notre microservice avec Clinic bubbleprof. Comme pour Clinic flame et Clinic doctor son utilisation est très simple, il suffit de lancer la commande suivante :
clinic bubbleprof [options] -- node server.jsLes options qui nous intéressent sont les suivantes :
--autocannon Permets de lancer autocannon en lui passant ses options entre [ ].--on-port Permets de lancer une commande une fois que l'application est en écoute sur un port.Je vous invite à lire la documentation pour voir les autres options.
Testons donc notre microservice :
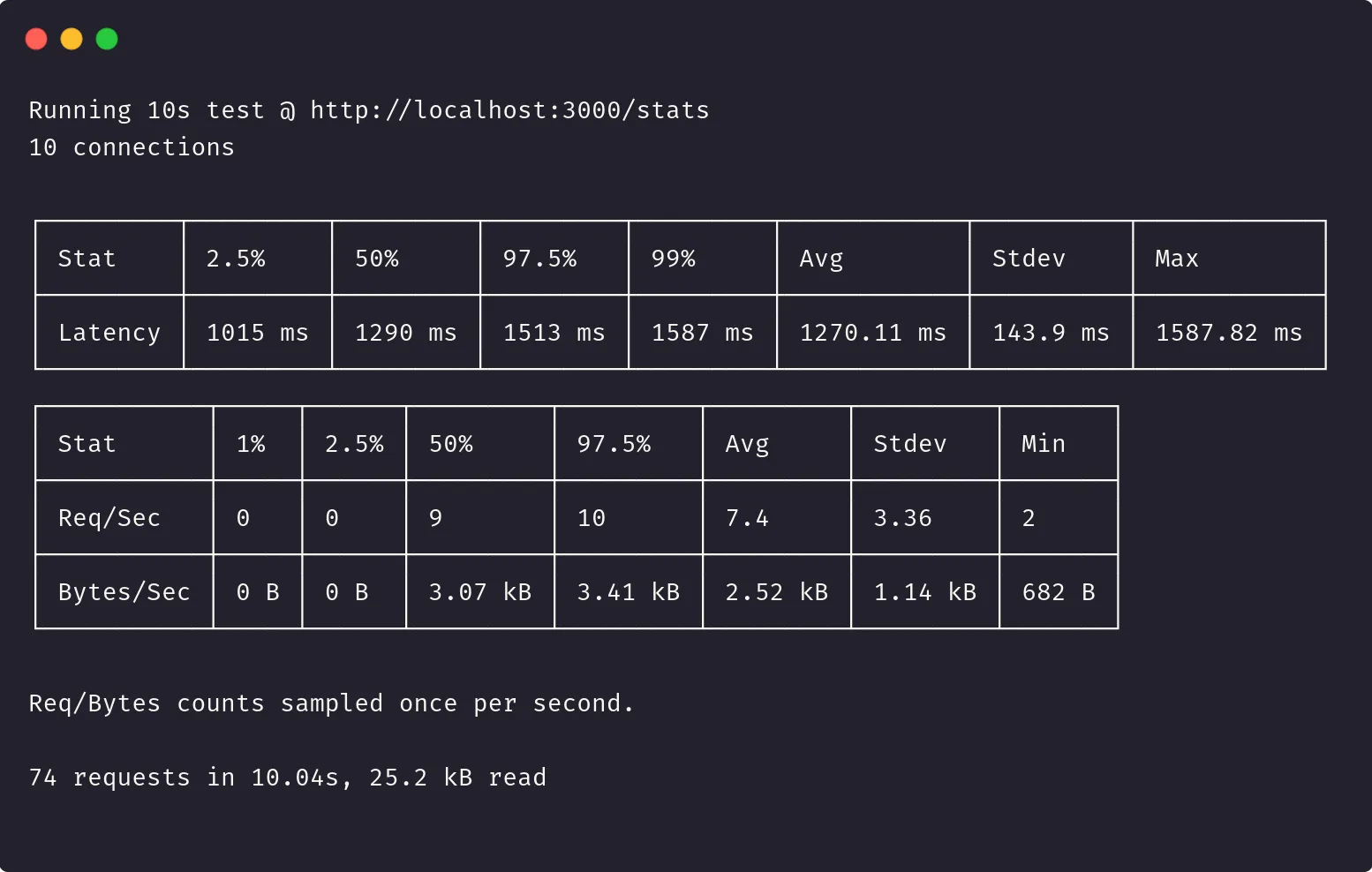
NODE_ENV=production clinic bubbleprof --autocannon [-c 10 /stats] -- node server.jsUne fois l’exécution terminée, on obtient le rapport autocannon suivant :
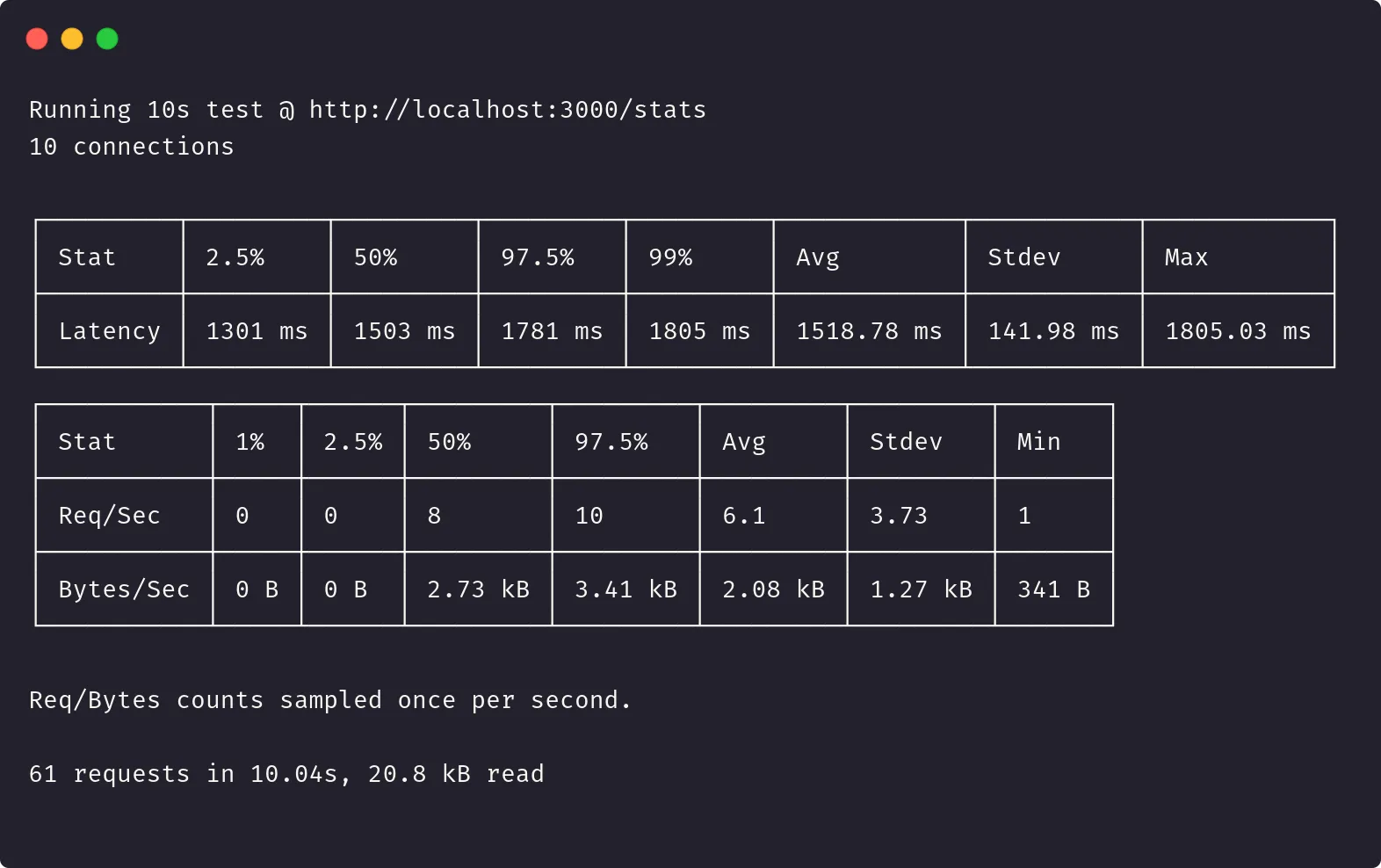
Uniquement 61 requêtes effectuées en 10 secondes…
Le rapport bubbleprof s’ouvre également dans une page web :
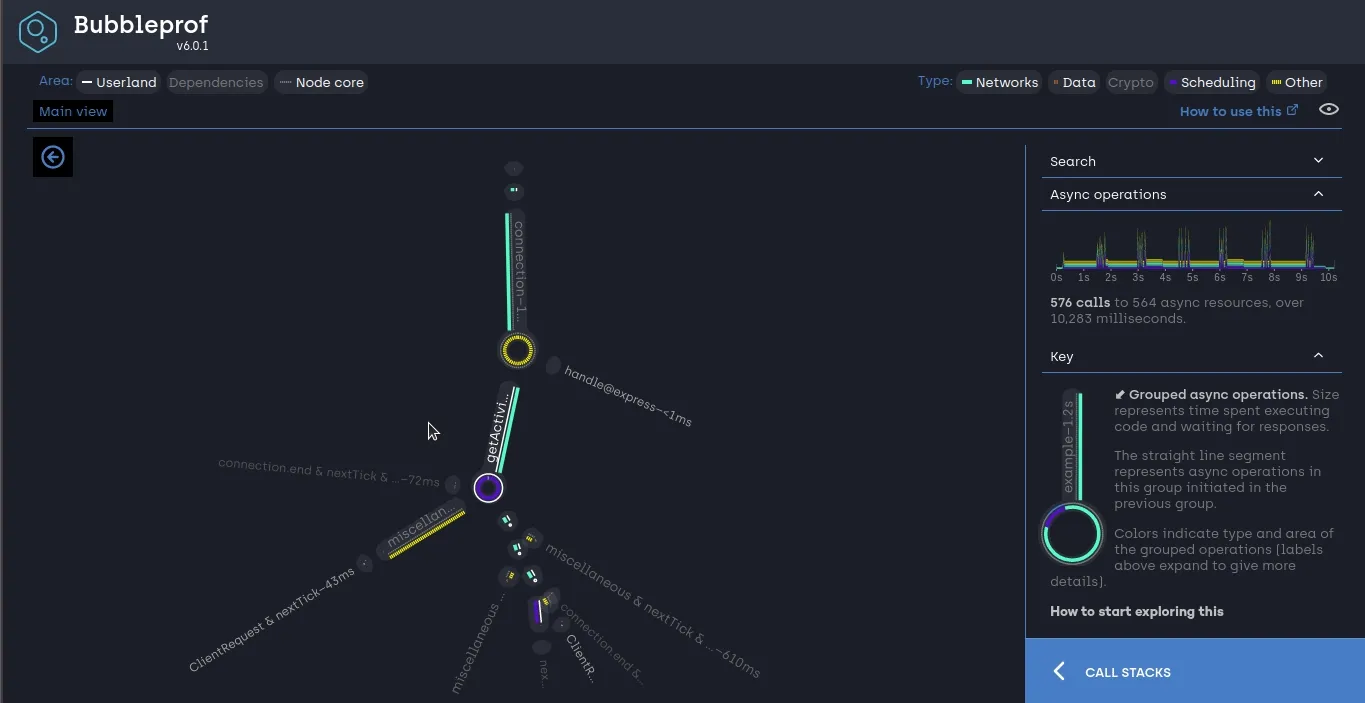
Restez là ! N’ayez pas peur je vais vous expliquer. Si vous le souhaitez vous pouvez trouver ce rapport ici.
Voyons donc comment interpréter le rapport généré par bubbleprof. Il y a plusieurs choses que vous devez impérativement retenir :
- Chaque bulle représente un groupe d’opérations asynchrones ;
- Plus le temps passé dans l’un de ces groupes est important, plus la taille de la bulle est grande;
- Les lignes entre chaque bulle informent sur l’ordonnancement des opérations asynchrones ;
- Plus les lignes entre les bulles sont longues, plus il existe de la latence entre elles ;
- Il existe différents types d’opérations (qui correspondent au type de ressources du module
async_hooksque l’on a vu précédemment) représentaient par une couleur :network(vert) : Il s’agit de toutes les opérations liées aux réseaux (les requêtes HTTP par exemple);data(orange) : Il s’agit des opérations liées principalement au modulefs;crypto(rose) : Il s’agit des opérations liées au module[crypto](https://nodejs.org/api/crypto.html);scheduling(violet) : Il s’agit des opérations liées aux timers et aux promesses;other(jaune) : Il s’agit des autres types d’opérations.
Analysons notre rapport. La première bulle jaune ne nous intéresse pas elle correspond simplement aux connexions HTTP des clients à notre microservice.
On remarque une première bulle bleue qui correspond à notre fonction getActivitiesStats, suivant de trois autres petites bulles qui correspond respectivement aux fonctions getFriendsStats, getPostsStats et getHealthStats.
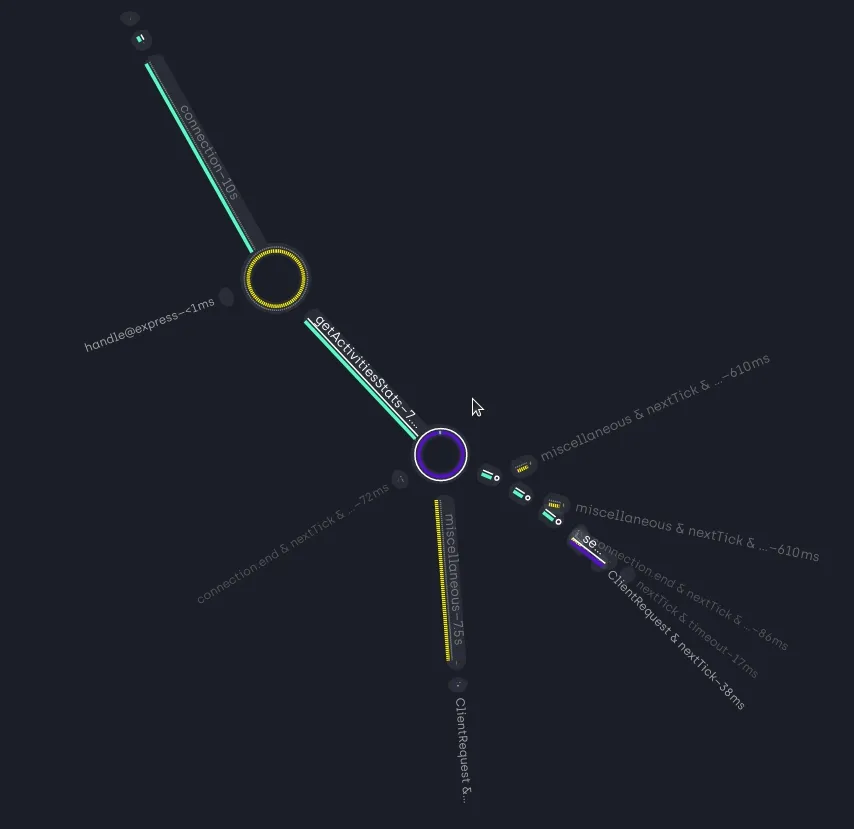
Si l’on clique sur la bulle correspond à la fonction getActivitiesStats nous avons des détails sur les opérations réalisées ainsi que sur la stack d’appels permettant de retrouver le code correspondant à la bulle.
Pour information, la ligne verte correspond à l’appel HTTP sur l’API du microservice et la ligne bleue correspond à la promesse associée à cet appel API.
On peut remarquer deux problèmes :
- Les appels API sont réalisés de façon séquentielle. En effet on remarque que la fonction
getHealthStatsest appelée après la fonctiongetPostsStatsqui elle-même est appelée après la fonctiongetFriendsStatsqui quant à elle est appelé après la fonctiongetActivitiesStats; - L’appel à la fonction
getActivitiesStatsprend environ 75 % du temps d’exécution.
Voyons ce qui cloche dans notre code. Pour le premier problème on remarque que l’on appelle effectivement nos promesses de façon séquentielle :
const activitiesStats = await getActivitiesStats()const friendsStats = await getFriendsStats()const healthStats = await getPostsStats()const postsStats = await getHealthStats()Nous attendons à chaque fois qu’une promesse soit terminée avant d’en appeler une autre. Nous devrions plutôt utiliser la méthode Promise.all comme suit :
const express = require('express')const { getActivitiesStats, getFriendsStats, getPostsStats, getHealthStats} = require('./services')
const app = express()
app.get('/stats', async (req, res, next) => { const activitiesStatsPromise = getActivitiesStats() const friendsStatsPromise = getFriendsStats() const healthStatsPromise = getPostsStats() const postsStatsPromise = getHealthStats()
const [activitiesStats, friendsStats, healthStats, postsStats] = await Promise.all( [ activitiesStatsPromise, friendsStatsPromise, healthStatsPromise, postsStatsPromise] )
res.json({ activities: activitiesStats, friends: friendsStats, health: healthStats, posts: postsStats })})
app.listen(3000, () => console.log('App listening at http://localhost:3000'))Relançons bubbleprof :
NODE_ENV=production clinic bubbleprof --autocannon [-c 10 /stats] -- node server.jsOn obtient le rapport autocannon suivant :
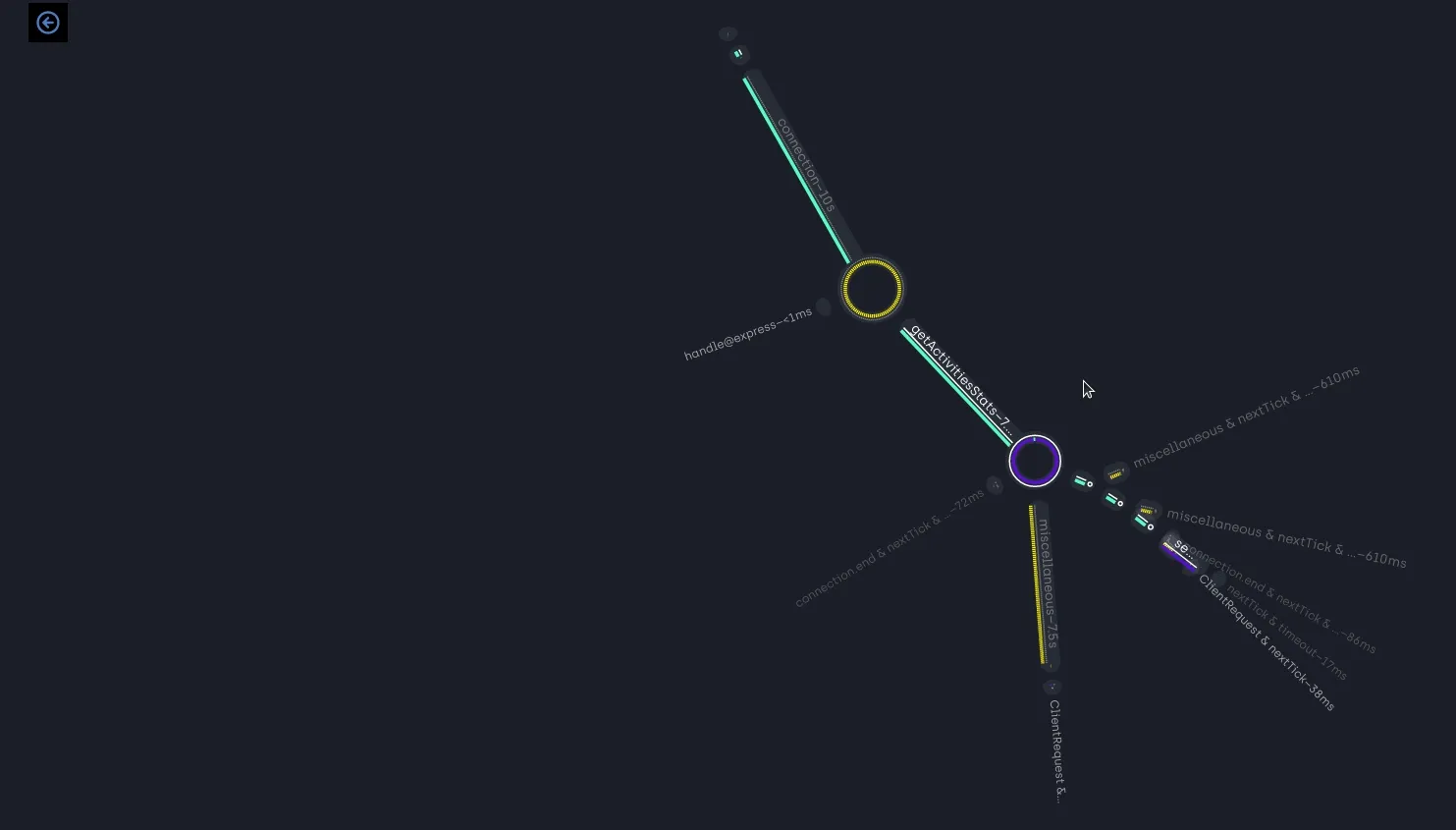
Ce n’est pas forcément mieux mais nous avons légèrement réduit la latence, due au fait que les appels APIs sont réalisés en parallèle.
Voyons le rapport bubbleprof (que vous pouvez retrouver ici):
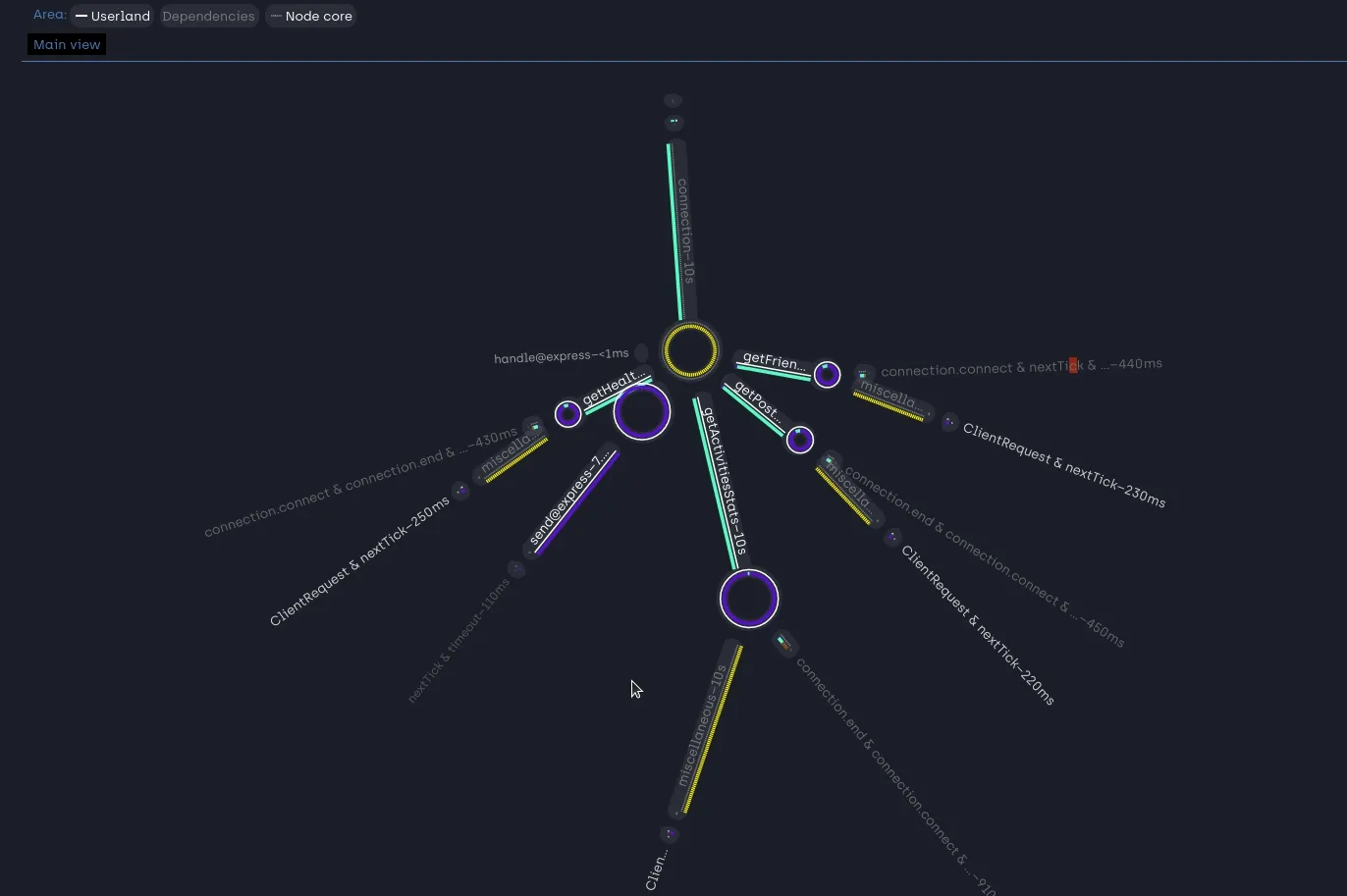
On observe comme je l’ai dit que nos appels APIs sont bien réalisés en parallèle. On observe également que la bulle correspond à notre fonction getActivitiesStats prend toujours la quasi-totalité du temps d’exécution.
La seconde grosse bulle bleue correspond simplement à notre instruction Promise.all qui regroupe les quatre promesses dont celle renvoyée par la fonction getActivitiesStats d’où la taille importante de la bulle.
Le principal problème reste donc notre promesse correspondant à la fonction getActivitiesStats qui met énormément de temps à être résolue. Il s’agit non pas d’un problème dans notre code mais simplement que le microservice gérant les activités sportives met beaucoup trop de temps à répondre. Nous devrions donc plutôt aller analyser ce microservice en question.
Par contre, il est possible dans notre microservice de statistiques de remédier à ce problème de latence. Pour cela il existe plusieurs solutions :
- Utiliser un système de cache qui éviterait de faire réaliser les appels API aux différents microservices et ainsi réduire la latence ;
- Renvoyer une réponse par défaut si une promesse mets trop de temps à être résolue.
Nous allons voir comment mettre en place cette deuxième solution. Pour cela nous avons besoin d’une fonction qui renvoie une promesse résolue après un certain délai :
function resolvePayloadAfter (delay, payload) { return new Promise((resolve) => { setTimeout(() => { resolve(payload) }, delay) })}Puis nous allons utiliser la méthode Promise.race qui permet de renvoyer la première promesse résolue ou rejetée :
const activitiesStatsPromise = Promise.race( [ getActivitiesStats(), resolvePayloadAfter(150, { error: 'Unavailable service' })],)const friendsStatsPromise = Promise.race( [ getFriendsStats(), resolvePayloadAfter(150, { error: 'Unavailable service' }), ])const healthStatsPromise = Promise.race( [ getPostsStats(), resolvePayloadAfter(150, { error: 'Unavailable service' }), ])const postsStatsPromise = Promise.race( [ getHealthStats(), resolvePayloadAfter(150, { error: 'Unavailable service' }), ])Si nos appels APIs mettent plus de 150 ms à répondre, une réponse par défaut sera renvoyée par la promesse de la fonction resolvePayloadAfter.
Si nous relançons bubbleprof :
NODE_ENV=production clinic bubbleprof --autocannon [-c 10 /stats] -- node server.jsNous obtenons le rapport autocannon suivant :
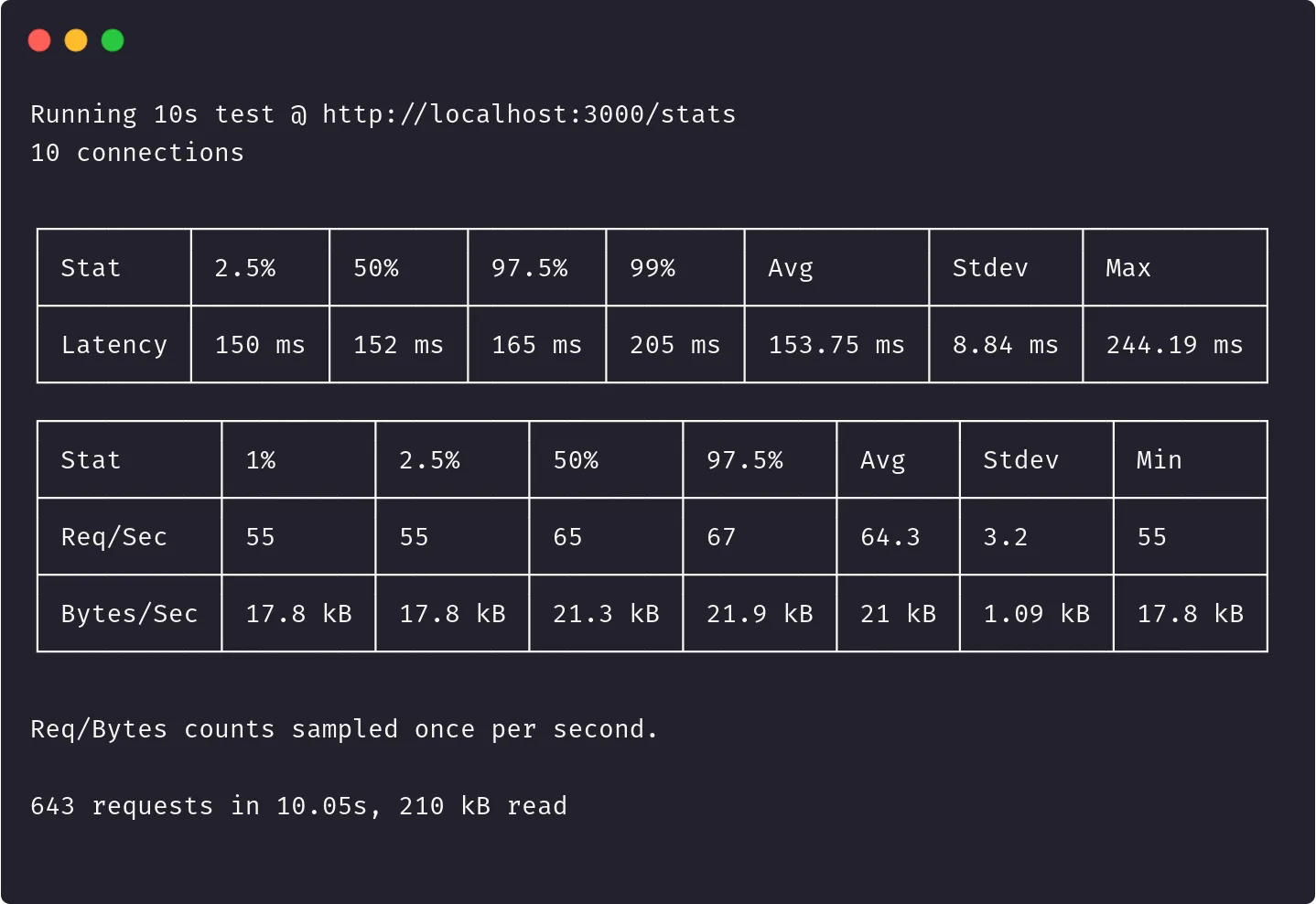
Nous avons cette fois-ci dix fois plus de requêtes effectués lors de ces 10 secondes de tests et un temps de réponse divisé par 10.
Ainsi que le rapport bubbleprof suivant (que vous pouvez également retrouver ici) :
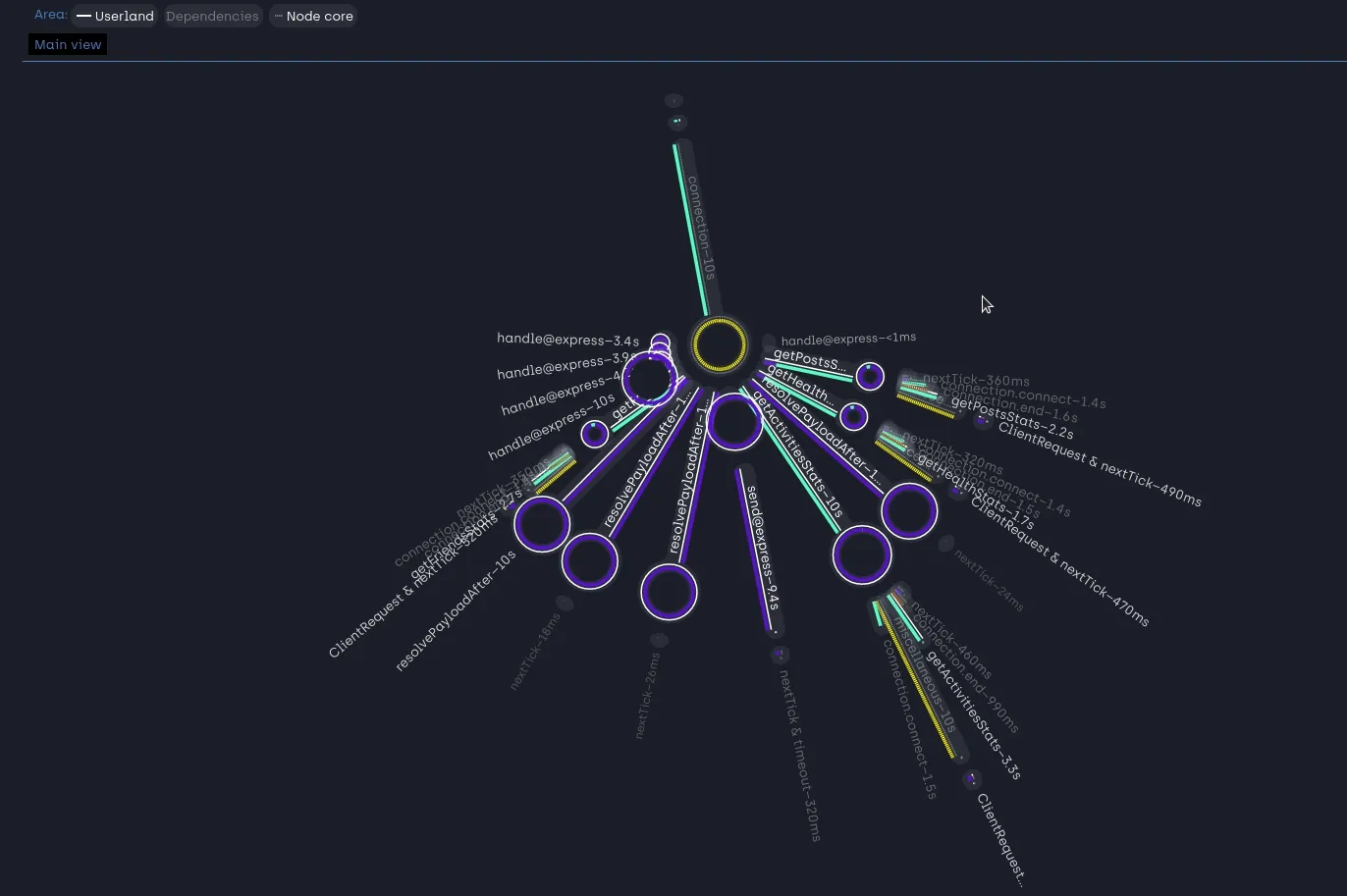
Le rapport n’est pas si différent du précédent à part l’apparition de quatre nouvelles grosses bulles bleues correspondant à la fonction resolvePayloadAfter qui est bien appelée quatre fois via la méthode [Promise.race](https://developer.mozilla.org/fr/docs/Web/JavaScript/Reference/Objets_globaux/Promise/race).
Ces quatre bulles occupent la totalité du temps d’exécution de notre test (10 secondes), pourquoi ? Simplement car lorsqu’une promesse est résolue (ou rejetée) la méthode [Promise.race](https://developer.mozilla.org/fr/docs/Web/JavaScript/Reference/Objets_globaux/Promise/race) n’annule pas les autres, celles-ci continuent jusqu’à ce qu’elles soient résolues (ou rejetées) d’où la présence de ces grosses bulles.
Notre microservice, via cette dernière solution fonctionne dans un mode dégradé. En effet bien que celui-ci prenne moins de temps, certaines réponses, concernant les statistiques, pourront contenir la valeur suivante :
{ error: 'Unavailable service'}C’est un choix assumé. Dans cet exemple nous préférons avoir des données absentes plutôt qu’un temps de réponse trop long.
Pour approfondir vos connaissances sur l’utilisation de Clinic bubbleprof, je vous conseille d’aller jeter un œil à la documentation officielle.
Et pour vous former à son utilisation, commencer par utiliser du code très simple comme celui-ci par exemple:
function sleep (ms) { return new Promise(resolve => setTimeout(resolve, ms))}Pour finir…
Nous venons de voir un exemple très simple pour illustrer l’utilisation de Clinic bubbleprof. Les problèmes de performances ne proviennent pas toujours de notre code, ceux-ci peuvent être dus à des services externes à notre application (bases de données mal optimisées, problème réseaux, disque dur trop lent, etc.) et il n’est pas toujours facile de trouver la source du problème sans les bons outils.
Ce troisième article vient clore le tour des outils classiques de cette série consacrée à l’analyse des performances des applications Node.js. Vous avez maintenant les bases pour analyser correctement les performances de vos applications.
On se retrouve dans un quatrième article, écrit cinq ans plus tard, pour voir à quoi ressemble le profiling quand c’est un agent IA qui mène l’enquête.



{kind=link}
{kind=link}
{kind=link}
Partage ta réflexion, pose une question ou laisse un retour.