
Deuxième article de cette série consacrée à l’analyse des performances des applications Node.js. Nous allons nous attaquer cette fois-ci à l’analyse de la mémoire. Pour rappel, cette série se compose de quatre articles :
- Analyse des performances CPU;
- Analyse de la mémoire;
- Analyse des traitements asynchrones;
- Un profiler pensé pour les agents IA.
J’essaye dans cet article d’être le plus exhaustif possible tout en essayant de garder l’article plaisant et simple à lire. C’est pourquoi certaines parties sont simplifiées et certains détails non essentiels sont omis (notamment sur l’organisation de la mémoire qui est un peu plus complexe que ça). Concernant le code présenté dans cet article, celui-ci est comme toujours simplifié pour se concentrer uniquement sur les concepts clés. Bonne lecture !
Organisation de la mémoire
Intéressons-nous à l’organisation de la mémoire de nos applications Node.js. Chaque programme en cours d’exécution occupe une certaine quantité de mémoire contenue dans la RAM. Cet espace mémoire est appelé la mémoire résidente (resident set size ou RSS). Celui-ci est découpé en deux segments la pile (stack) et le tas (heap).
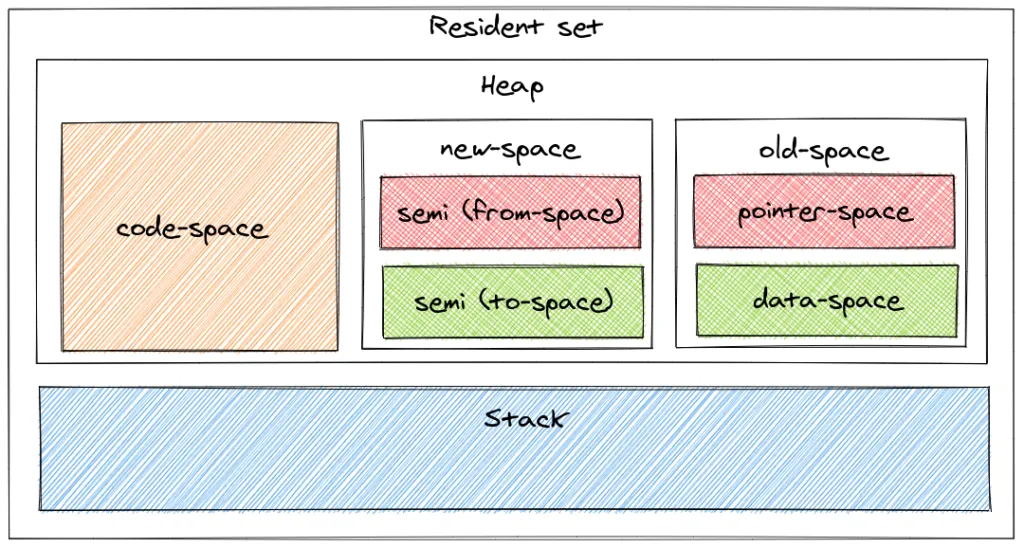
La pile (Stack)
La pile ou stack permet de stocker les types primitifs (number, string, boolean, etc.) ainsi que les références aux objets.
Le tas (Heap)
Le tas ou heap quant à lui permet de stocker les objets (Function, Object, Array, etc.). Celui-ci est découpé en plusieurs parties :
-
code-space : C’est ici que le code compilé à la volée est stocké;
-
new-space : C’est dans cet espace que les objets nouvellement crées sont stockés. La durée de vie ces objets est généralement courte. Le nettoyage de cet espace est réalisé par le premier garbage collector (minor GC). cet espace est découpé en deux autres espaces (from-space et to-space). Mais on en reparlera plus en détail un peu plus tard;
-
old-space : Les objets stockés dans l’espace new-space ayant survécu à un certain nombre de cycles du premier garbage collector (deux cycles pour être exact) sont transférés dans cet espace. Le nettoyage de celui-ci est réalisé par le second garbage collector (major GC). cet espace est lui-même découpé en deux autres espaces à savoir :
- pointer-space : Contient les objets contenant une référence vers d’autres objets;
- data-space : Contient les objets constitués uniquement de types primitifs (
number,string,boolean, etc.) c’est-à-dire ceux ne contenant aucune référence vers d’autres objets.
Garbage collector
Contrairement à d’autres langages comme le C ou C++, la mémoire allouée dynamiquement d’un programme Node.js est “automatiquement” libérée. Cette libération automatique est réalisée par un garbage collector ou ramasse-miette en français. Comme nous l’avons vu, Node.js utilise deux garbage collectors : minor GC (scavenge) et major GC (mark-sweep-compact).
Minor GC (scavenge)
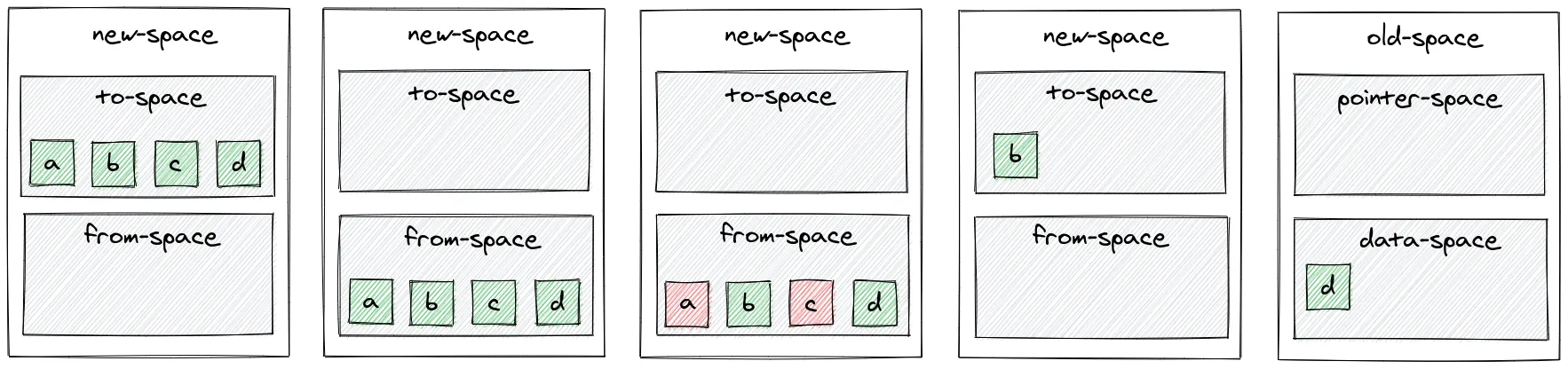
Ce premier garbage collector, est uniquement exécuté dans l’espace new-space du tas (heap). Celui-ci est exécuté régulièrement sur une petite quantité de mémoire (entre 1 et 8 mégaoctets). Son fonctionnement est le suivant :
-
L’allocation d’un nouvel objet se fait dans l’espace to-space;
-
S’il n’y a plus d’espace disponible dans l’espace to-space le garbage collector s’exécute;
-
On permute les espaces to-space et from-space. L’espace from-space devient donc l’espace to-space;
-
Le garbage collector parcourt l’ensemble des objets présent dans l’espace from-space et pour chacun de ces objets, vérifie si celui-ci est toujours utilisé. Si c’est le cas, deux scénarios sont possibles :
- Les objets sont déplacés dans l’espace to-space. Si ces objets ont des références vers d’autres objets, ceux-ci sont également déplacés;
- Si les objets sont présents dans l’espace new-space depuis plus de deux cycles du garbage collector, ceux-ci (ainsi que les objets qu’ils référencent) sont placés dans l’espace old-space.
-
Les objets non utilisés sont désalloués;
Major GC (Mark-sweep-compact)
Ce second garbage collector, s’exécute dans l’espace old-space comme vu précédemment. Son principe est très simple et repose sur trois phases mark, sweep et compact.
Mark
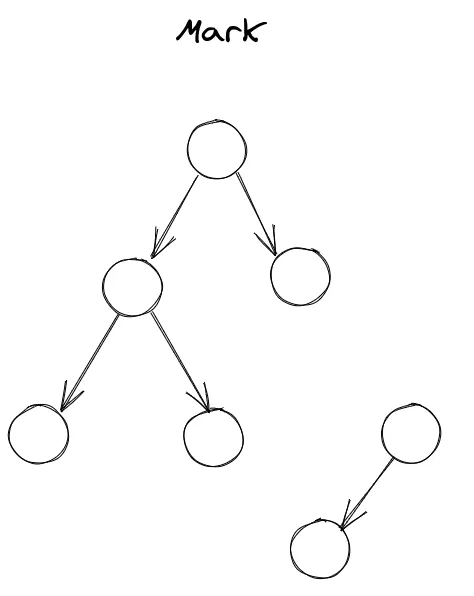
Pour mieux comprendre la suite, on peut représenter la mémoire comme un graphe où chaque nœud est un objet et chaque arête, une référence vers un autre objet. La première phase consiste donc à parcourir ce graphe (en utilisant l’algorithme de parcours en profondeur) et marquer chaque nœud comme suit :
- Blanc : Il s’agit de l’état initial signifiant que l’objet n’a pas été découvert par le garbage collector;
- Gris : L’objet a été découvert, mais l’ensemble de ces voisins (les objets dont il possède des références) ne sont pas encore traités par le garbage collector;
- Noir : L’objet ainsi que l’ensemble de ses voisins ont été traités par le garbage collector.
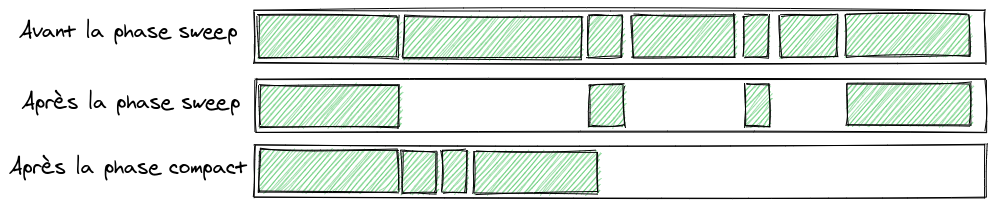
Sweep
Cette phase est très simple, puisqu’elle consiste simplement à libérer la mémoire des objets non marqués de la phase précédente, c’est-à-dire dire ceux en blanc.
Compact
Lors de la phase précédente, la mémoire se trouve fragmentée. Cette dernière étape consiste donc à optimiser la mémoire en réorganisant celle-ci.
Si vous souhaitez plus d’informations sur ces deux garbage collectors, n’hésitez pas à aller jeter un coup d’œil sur cette documentation : V8 Garbage Collector
Détection des fuites mémoires
Après avoir vu le fonctionnement de la mémoire, il est temps de s’attaquer à l’analyse de celle-ci et plus particulièrement à la détection des fuites mémoires.
Qu’est-ce qu’une fuite mémoire ?
Une fuite mémoire est simplement l’absence de libération de l’espace occupé par des objets censés ne plus être utilisés et qui a pour conséquence l’augmentation de l’occupation mémoire pouvant provoquer des soucis de performance.
Les causes des fuites mémoires
Comme nous l’avons vu, les garbage collectors libèrent de l’espace mémoire occupé par les objets qui ne sont plus utilisés. Une fuite mémoire apparaît donc quand des références aux objets censés être libérés existent encore. Les fuites mémoires sont toujours dues à une erreur de programmation de la part des développeurs. Nous allons voir une liste non exhaustive de cas provoquant des fuites mémoires.
les variables globales
Les variables globales ne sont jamais libérées par le garbage collector, car celles-ci sont toujours référencées par l’objet global qui n’est lui n’est jamais libéré.
Dans le code suivant, la variable result est une variable globale bien que celle-ci ait était défini dans la fonction randomIntegerBetween. Cela est dû au principe de l’hoisting :
function randomIntegerBetween (min, max) { result = Math.floor(Math.random() * (max - min + 1) + min) return result}
console.log(randomIntegerBetween(1, 10)) // affiche un nombre entre 1 et 10console.log(result) // affiche le même résultat que l'instruction précédente, car result est une variable globaleLa solution à ce problème est bien entendu d’utiliser les mots clés let ou const pour créer la variable dans le scope de la fonction :
function randomIntegerBetween (min, max) { const result = Math.floor(Math.random() * (max - min + 1) + min) return result}Il est également conseiller d’utiliser le mode strict pour éviter ce type d’erreur :
'use strict'
function randomIntegerBetween (min, max) { result = Math.floor(Math.random() * (max - min + 1) + min) // ReferenceError: result is not defined return result}Attention également à l’utilisation du mot clé this.
const obj = { value: null, setValue: (value) => { this.value = value }}
function process (callback) { const arr = []
/* ... traitement sur le tableau arr */
callback(arr)}
console.log(exports) // l’objet global exports est vide {}
process(obj.setValue)
console.log(obj.value) // affiche null, la propriété value de obj n'a pas été affectée...console.log(exports) // ... c'est l'objet global exports qui a vu sa propriété value créée et assignéeLes closures
Petit rappel, une closure est une fonction interne à une autre fonction qui va pouvoir accéder aux variables de cette dernière, et ce même si celle-ci a été exécutée.
Petit exemple :
function outer () { const a = 10
function inner () { const b = 20 console.log(a + b) }
return inner}
const func = outer()
func() // affiche 30, la variable "a" contenue dans la fonction outer n'a pas été suppriméeLe moteur V8 est intelligent et ne garde en mémoire que les variables qui sont réellement utilisées dans la closure :
function outer () { const a = 10 const unused = new Array(100000) // le tableau sera désalloué à la fin de la fonction outer
function inner () { const b = 20 console.log(a + b) }
return inner}
const func = outer()func()Mais il y a un cas qui peut créer une fuite mémoire :
function outer () { const a = 10 const unused = new Array(100000) // le tableau ne sera pas désalloué à la fin de la fonction outer
function private () { console.log(unused) }
function inner () { const b = 20 console.log(a + b) debugger; // on met un point d'arrêt pour tester l'existence de la variable unused }
return inner}
const func = outer()func()Testons notre code :
node --inspect-brk index.jsDébuggons celui-ci dans Chrome. Ouvrons la page about:inspect :
On remarque que même si la variable unused n’est pas utilisée dans la closure inner, celle-ci est toujours présente en mémoire.
Pensez donc à toujours faire attention lorsque vous utilisez des closures, ce cas particulier arrive bien plus souvent qu’on ne le pense et il est souvent difficile de l’apercevoir.
Bonus : Il est possible également de débugger directement depuis la console via la commande :
node inspect index.js
Maintenant, comment éviter ce genre de problème ? Pour commencer, éviter de déclarer des variables non utilisées faisant référence à un type non primitif, comme Object, Array, Function, etc. (merci captain obvious…).
Une autre astuce consiste à assigner aux variables la valeur null à la fin de la fonction pour “supprimer” la référence vers les objets. Ces derniers pourront ainsi être recyclées par le garbage collector :
function outer () { const a = 10 let unused = new Array(100000) // la variable ne sera pas désallouée à la fin de la fonction outer
function private () { console.log(unused) }
function inner () { const b = 20 console.log(a + b) debugger; // on met un point d'arrêt pour tester l'existence de la variable unused }
unused = null // la référence au tableau n'existe plus celui-ci sera recyclé par le GC
return inner}
const func = outer()func()Les promesses
Nous allons voir un cas de fuite mémoire provoqué par l’utilisation des promesses. Il arrive parfois (quand le code est mal conçu) qu’une promesse ne soit jamais résolue et reste dans l’état pending. L’exécution du code est donc suspendue à la résolution de la promesse qui n’arrivera jamais. Toutes les variables appartenant au scope de cette exécution en attente, ne seront donc pas libérées par le garbage collector, puisque celles-ci sont toujours référencées. Voici un exemple de code illustrant ce problème :
const express = require('express')
const app = express()
const canBeUnresolved = () => { return new Promise((resolve) => { const random = Math.random() if (random < 0.5) { resolve() } })}
app.get('/', async (req, res) => { await canBeUnresolved() // Le code qui suit peut ne jamais être atteint res.end()})
app.listen(3000)Dans cet exemple, toutes les variables déclarées avant l’attente de la promesse (via l’instruction await) persistent en mémoire. En plus d’une fuite mémoire, nous avons une fuite concernant les descripteurs de fichiers. Les descripteurs de fichiers sont des identifiants pour les fichiers, les dossiers, les sockets réseau, etc. Leur nombre est limité par le système d’exploitation et comme pour la mémoire, ceux-ci doivent être libérés. Dans notre exemple, nous avons une connexion réseau qui ne sera pas fermée du fait de l’attente de la promesse.
Une solution à ce problème consiste à pouvoir stopper la promesse au bout d’un certain délai. Pour cela, nous allons utiliser la méthode Promise.race qui renvoie la première promesse terminée (résolue ou rejetée) :
const express = require('express')
const app = express()
function cancelAfter (delay) { return new Promise((resolve, reject) => { setTimeout(() => { reject(`timeout of ${delay}ms exceeded`) }, delay) })}
const canBeUnresolved = () => { return new Promise((resolve) => { const random = Math.random() if (random < 0.5) { resolve() } })}
app.get('/', async (req, res) => { try { await Promise.race([canBeUnresolved(), cancelAfter(5000)]) // On rejète la promesse après 5 secondes res.end() } catch (err) { res.status(408).send(err) }})
app.listen(3000)D’autres exemples
Nous avons vu quelques cas qui provoquent des fuites mémoires, mais il en existe bien d’autres. Par exemple :
- Une mauvaise utilisation de la méthode
pipedes streams qui provoque une mauvaise fermeture de l’un d’eux. Il est d’ailleurs recommandé d’utiliser la méthodepipeline; - Une mauvaise stratégie de cache, comme une absence de nettoyage de celui-ci qui fait gonfler l’utilisation de la mémoire;
- Les gestionnaires d’événements (
EventEmitter) qui ne sont pas correctement supprimés (viaremoveListener) ou qui s’exécutent plusieurs fois (viaonau lieu deonce); - Les timers (
setIntervalousetTimeout) qui ne sont pas correctement supprimés lorsqu’il est nécessaire (respectivement viaclearIntervalouclearTimeout); - De multiples références à un objet peuvent également provoquer des fuites mémoires, car comme nous l’avons vu, le garbage collector désalloue les données quand il n’y a plus de référence à celles-ci;
Comment détecter les fuites mémoires ?
Nous allons maintenant voir comment détecter les fuites mémoires. Prenons un exemple très simple afin de voir comment utiliser les outils. On parlera un peu plus tard d’un cas concret qu’il m’est arrivé il y a quelque temps. L’exemple que l’on va prendre est le suivant :
const express = require('express')const imageManager = require('./imageManager')const app = express()
const cache = {}
app.get('/images/random', async (req, res) => { const id = await imageManager.randomId() if (cache[id]) { return res.json(cache[id]) } const image = await imageManager.getById(id) cache[id] = image return res.end(image)})
app.listen(3000)Ce code permet de récupérer des images de façon aléatoire et de sauvegarder celle-ci dans un cache en mémoire afin d’éviter d’aller rechercher celle-ci sur le disque dur.
process.memoryUsage()
Node.js permet d’obtenir des informations sur la consommation mémoire via le module process et sa méthode memoryUsage :
console.log(process.memoryUsage())/*{ rss: 45395968, heapTotal: 15532032, heapUsed: 9228672, external: 1301057, arrayBuffers: 58794}*/Cette méthode renvoie un objet avec comme propriété :
rss: le montant total de la mémoire occupé par l’application;heapTotal: Le montant total de la mémoire du tas alloué pour les objets;heapUsed: Le montant de la mémoire du tas occupé par les objets;external: Le montant de la mémoire utilisé par les objets C++;arrayBuffers: La mémoire allouée pour lesArrayBuffer,SharedArrayBufferetBuffer. Ce montant est inclus dans celui deexternal.
Ces valeurs sont exprimées en octets.
Il existe également les méthodes getHeapSpaceStatistics et getHeapStatistics du module v8.
Clinic doctor
Nous avons vu dans le précédent article l’outil clinic flame. Aujourd’hui, nous allons nous intéresser à l’outil clinic doctor. Pour cela installons clinic :
npm install -g clinicPour utiliser clinic doctor, il suffit de lancer la commande suivante :
clinic doctor [options] -- node index.jsLes options qui nous intéressent sont les suivantes :
--autocannon Permets de lancer autocannon en lui passant ses options entre [ ].--on-port Permets de lancer une commande une fois que l'application est en écoute sur un port.Je vous invite à lire la documentation pour voir les autres options.
Analysons donc notre route avec la commande suivante :
NODE_ENV=production clinic doctor --autocannon [/images/random] -- node index.jsUne fois l’exécution terminée, une page web s’ouvre :
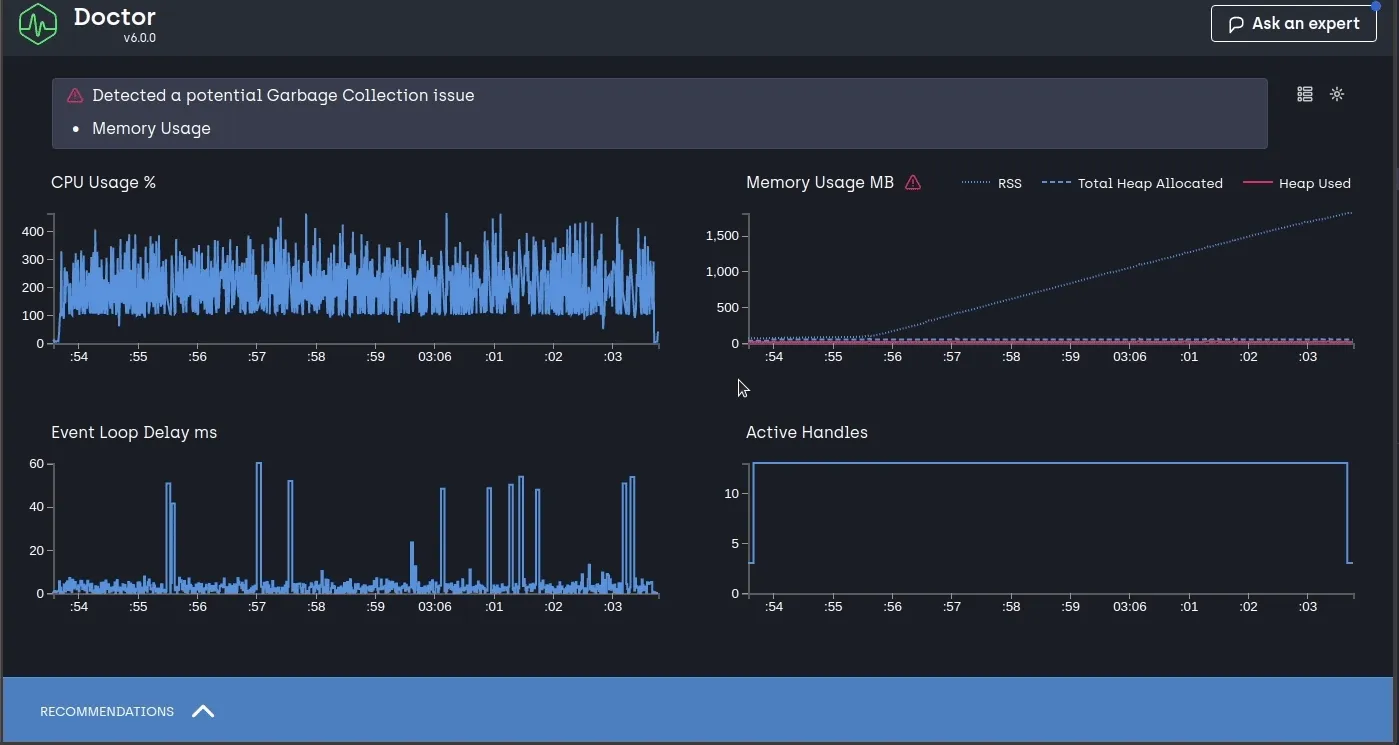
doctor clinic donne plusieurs graphiques intéressants :
CPU usage: l’utilisation du CPU exprimée en pourcentage;Memory usage: l’utilisation de la mémoire exprimée en mégaoctets. Les trois courbes représentent respectivement la mémoire résidente (RSS), le total de mémoire du tas allouée (Total Heap Allocated) et la mémoire du tas utilisée (Heap Used).**Event loop delay**: La latence de la boucle d’événements exprimée en millisecondes;Active handles: Les descripteurs de fichiers ouverts (sockets, fichiers, etc.).
Le graphique qui nous intéresse est celui qui concerne l’utilisation de la mémoire. On remarque que la mémoire résidente (RSS) augmente au fur et à mesure ce qui est un signe de fuite mémoire.
Pour ceux que ça intéresse, vous pouvez retrouver ce rapport ici.
Chrome devTools
Nous avons découvert avec clinic doctor une fuite mémoire, maintenant il faut trouver la source de celle-ci. Pour cela nous allons utiliser Chrome devTools, prendre deux snapshots de notre mémoire et les comparer. Pour commencer, lançons notre application avec l’option --inspect:
NODE_ENV=production node --inspect index.jsOuvrons ensuite chrome et ouvrons la page web about:inspect
Cliquons sur inspect et prenons notre premier snapshot Memory -> Heap snapshot -> Take snapshot
La vue suivante s’ouvre avec notre premier snapshot :
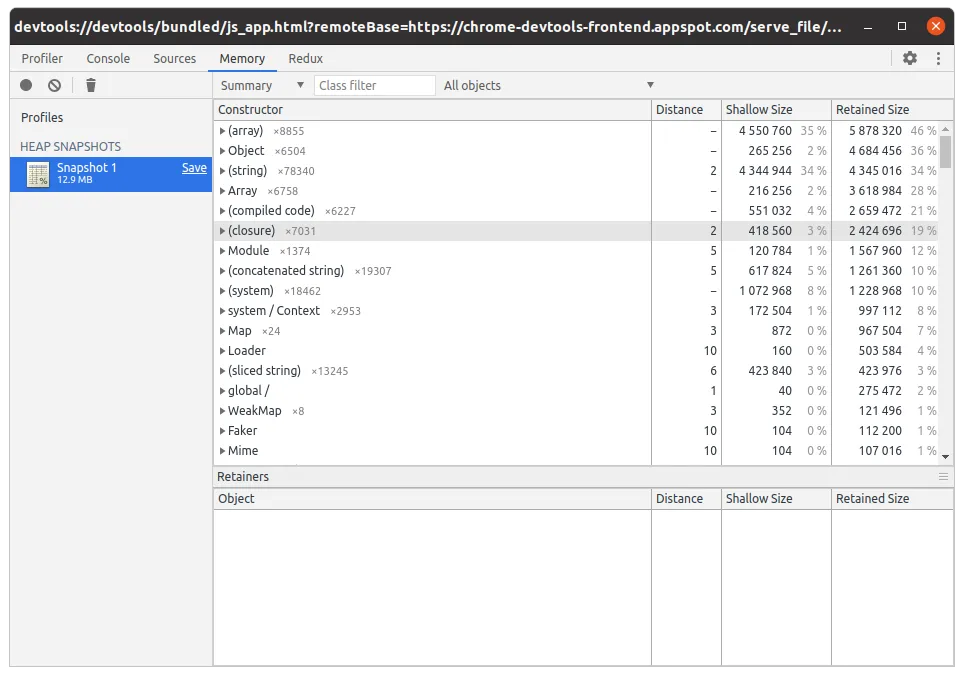
Lançons ensuite la commande autocannon suivante :
autocannon localhost:3000/images/randomPuis prenons un second snapshot. Pour cela il suffit de cliquer sur Profiles au-dessus du premier snapshot puis Heap snapshot ->Take snapshot
Nous pouvons dès maintenant comparer les deux snapshots :
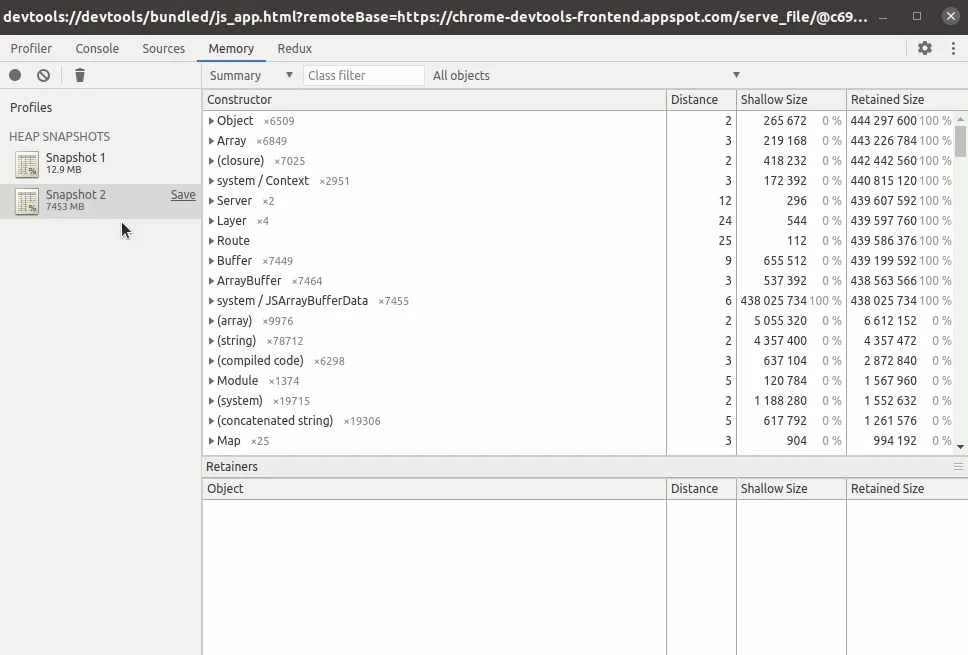
Nous pouvons voir le delta entre les deux snapshots (Delta et SizeDelta). Nous remarquons qu’il y a un nombre important de nouveaux objets de type ArrayBuffer. Si nous déroulons la ligne correspondante, nous pouvons accéder à l’ensemble de ces nouveaux objets et voir où ceux-ci ont été créés.
Dans notre cas, il s’agit de la variable cache contenu dans notre fichier index.js. Les objets ArrayBuffer correspondent donc aux buffers de nos images.
Résoudre le problème
Le problème est assez simple à résoudre, nous stockons toutes les images récupérées, via notre route, dans la mémoire. Il nous faut donc stocker un nombre limité d’images et avoir une gestion de cache plus efficace. Une solution très simple est d’utiliser un cache LRU (Least-Recently-Used) qui permet de garder en cache uniquement les images récemment utilisées.
Ça tombe bien, un module Node.js existe sur npm, installons celui-ci :
npm install --save lru-cacheModifions ensuite notre code :
const express = require('express')const LRU = require('lru-cache')const imageManager = require('./imageManager')
const app = express()
const cache = new LRU({ max: 50 // On garde que 50 images en mémoire})
app.get('/images/random', async (req, res) => { const id = await imageManager.randomId() if (cache.has(id)) { return res.json(cache[id]) } const image = await imageManager.getById(id) cache.set(id, image)
return res.end(image)})
app.listen(3000)Lançons ensuite clinic doctor :
NODE_ENV=production clinic doctor --autocannon [/images/random] -- node index.jsOn obtient le rapport suivant :
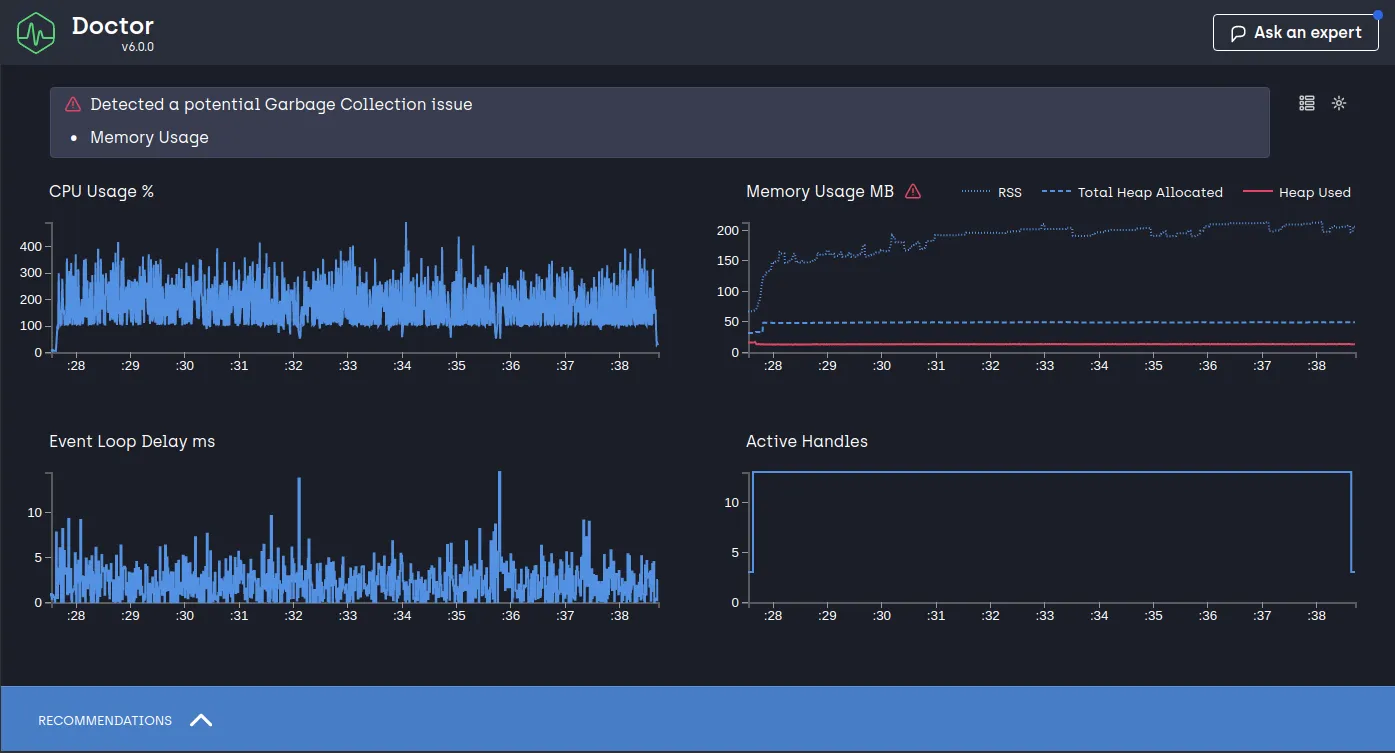
Nous avons divisé la consommation mémoire par 8 et l’utilisation du cache LRU nous permet d’avoir plus de contrôle sur la consommation de la mémoire.
Analyser en production
Voyons comment il est possible de récupérer un dump de la mémoire en production. Node fournit, via le module v8, depuis la version 11.13.0, une méthode getHeapSnapshot permettant de générer un dump de la mémoire. Ajoutons donc une route permettant de générer et télécharger ce fichier de dump :
const express = require('express')const v8 = require('v8')const { pipeline } = require('stream')const { promisify } = require('util')
const pipelineAsync = promisify(pipeline)
app.get('/snapshot', async (req, res) => { try { const heapDumpStream = v8.getHeapSnapshot()
res.set({ 'Content-Type': 'text/plain', 'Content-disposition': `attachment; filename="Heap-${(new Date()).toISOString()}.heapsnapshot"` })
await pipelineAsync(heapDumpStream, res) } catch (err) { res.status(500).send({ message: 'Internal error server' }) }})Pour les versions de Node inférieure à la 11.13.0, vous pouvez utiliser le module heapdump :
npm install --save heapdumpEt utiliser le code suivant :
const fs = require('fs')const heapdump = require('heapdump')const { pipeline } = require('stream')const { promisify } = require('util')
const pipelineAsync = promisify(pipeline)const writeSnapshotAsync = promisify(heapdump.writeSnapshot)
app.get('/snapshot', async (req, res) => { try { const heapDumpFileName = await writeSnapshotAsync() const heapDumpStream = fs.createReadStream(heapDumpFileName)
res.set({ 'Content-Type': 'text/plain', 'Content-disposition': `attachment; filename="Heap-${(new Date()).toISOString()}.heapsnapshot"` })
await pipelineAsync(heapDumpStream, res) } catch (err) { res.status(500).send({ message: 'Internal error server' }) }})Voilà ! il ne reste plus qu’à ouvrir le fichier généré dans chrome devTools :
Cas concret (ou comment raconter sa vie)
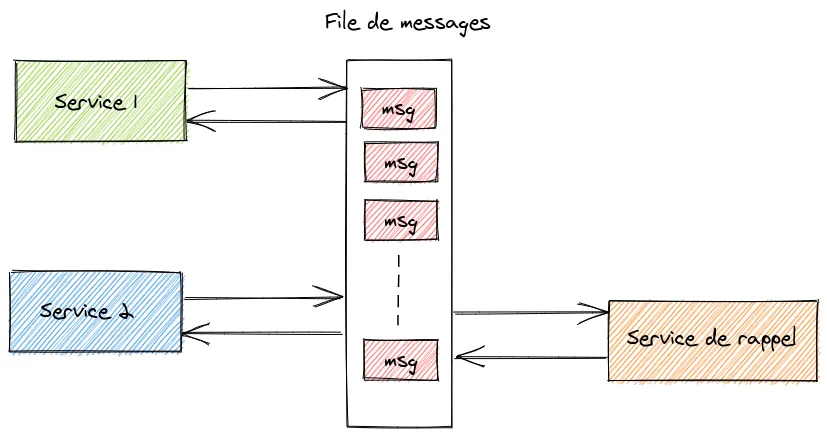
Avant de terminer, j’aimerais vous parler d’un problème qu’il m’est arrivé il y a quelque temps. Je travaillais sur une architecture microservices permettant à chacun des services d’enregistrer des tâches à effectuer plus tard dans un autre service servant en quelque sorte de service de rappel.
Le tout communiquait ensemble via une file de messages. Bref je ferais sûrement un article sur l’architecture microservices un jour pour expliquer tout ça.
Ce service de rappel ne disposait pas de base de données et les tâches étaient directement enregistrées en mémoire. Je devais rajouter pour ce service de rappel, une API permettant de récupérer les tâches mais également leur attacher des informations complémentaires. Sauf que je ne pouvais pas modifier le code existant concernant la gestion des tâches (principe ouvert/fermé tout ça tout ça).
Donc c’est tout, je décide d’utiliser l’objet Map et d’ajouter les informations complémentaires des tâches dans celle-ci. Le code ressemblait plus ou moins à ca :
const express = require('express')const taskManager = require('./taskManager')
const app = express()app.use(express.json())app.use(express.urlencoded({ extended: true }))
const tasksMeta = new Map()
app.post('/tasks/:uuid/meta', (req, res) => { const { uuid } = req.params const task = taskManager.getByUUID(uuid) if (!task) { return res.status(404).json({ message: 'Task not found' }) }
const previousMeta = tasksMeta.get(task) const newMeta = { ...previousMeta, ...req.body } tasksMeta.set(task, newMeta) return res.sendStatus(newMeta)})
app.get('/tasks/:uuid', (req, res) => { const { uuid } = req.params const task = taskManager.getByUUID(uuid) if (!task) { return res.status(404).json({ message: 'Task not found' }) }
const meta = tasksMeta.get(task) return res.json({ task, meta })})
app.listen(3000)Ça fonctionnait bien, j’étais content et cela ne m’avait pas pris beaucoup temps. Sauf que, la consommation mémoire ne faisait que d’augmenter et ce que je n’avais pas prévu (bouh le nul), c’est que les tâches, une fois celles-ci terminées, étaient supprimées. Mais la Map, que j’avais ajoutée, contenant les informations complémentaires avait toujours une référence vers les tâches supprimées puisque celles-ci servaient de clé.
Donc en plus d’avoir les informations complémentaires qui n’était pas supprimées en même temps que les tâches, ces dernières n’étaient également pas nettoyées par le garbage collector. Et pour couronner le tout, je ne pouvais pas modifier le code source existant concernant la suppression des tâches et je n’avais aucun moyen d’être mis au courant (via un event par exemple). Mais alors j’ai fait comment ? C’est simple, j’ai utilisé l’objet WeakMap :
const tasksMeta = new WeakMap()La WeakMap permet d’utiliser des objets comme clé tout comme la Map. La seule différence est que la clé est une référence “faible” vers l’objet en question. Ce qui signifie que s’il n’existe plus aucune référence vers cet objet excepté celle servant de clé, le garbage collector est autorisé à nettoyer cet objet.
Dans mon cas, si la tâche est supprimée ailleurs dans le code (et que plus aucune variable ni fait référence), les informations complémentaires de celle-ci contenues dans ma WeakMap ainsi que la tâche en question pourront être nettoyées par le garbage collector.
Pour finir
Nous venons de voir comment fonctionnait la mémoire dans une application Node.js et comment il était possible d’identifier les fuites mémoires.
Tout comme l’analyse des performances CPU, le sujet est très vaste. J’ai essayé d’être le plus exhaustive possible dans cet article et j’espère que celui-ci vous a plu.
On se retrouve la prochaine fois pour le troisième article de cette série et on se penchera cette fois-ci à l’analyse des traitements asynchrones.



{kind=link}
Partage ta réflexion, pose une question ou laisse un retour.